分类: 未分类
micropython esp wifi 配置
wifimgr.py
import network
import socket
import ure
import time
ap_ssid = "WifiManager"
ap_password = "tayfunulu"
ap_authmode = 3 # WPA2
NETWORK_PROFILES = 'wifi.dat'
wlan_ap = network.WLAN(network.AP_IF)
wlan_sta = network.WLAN(network.STA_IF)
server_socket = None
def get_connection():
"""return a working WLAN(STA_IF) instance or None"""
# First check if there already is any connection:
if wlan_sta.isconnected():
return wlan_sta
connected = False
try:
# ESP connecting to WiFi takes time, wait a bit and try again:
time.sleep(3)
if wlan_sta.isconnected():
return wlan_sta
# Read known network profiles from file
profiles = read_profiles()
# Search WiFis in range
wlan_sta.active(True)
networks = wlan_sta.scan()
AUTHMODE = {0: "open", 1: "WEP", 2: "WPA-PSK", 3: "WPA2-PSK", 4: "WPA/WPA2-PSK"}
for ssid, bssid, channel, rssi, authmode, hidden in sorted(networks, key=lambda x: x[3], reverse=True):
ssid = ssid.decode('utf-8')
encrypted = authmode > 0
print("ssid: %s chan: %d rssi: %d authmode: %s" % (ssid, channel, rssi, AUTHMODE.get(authmode, '?')))
if encrypted:
if ssid in profiles:
password = profiles[ssid]
connected = do_connect(ssid, password)
else:
print("skipping unknown encrypted network")
else: # open
connected = do_connect(ssid, None)
if connected:
break
except OSError as e:
print("exception", str(e))
# start web server for connection manager:
if not connected:
connected = start()
return wlan_sta if connected else None
def read_profiles():
with open(NETWORK_PROFILES) as f:
lines = f.readlines()
profiles = {}
for line in lines:
ssid, password = line.strip("\n").split(";")
profiles[ssid] = password
return profiles
def write_profiles(profiles):
lines = []
for ssid, password in profiles.items():
lines.append("%s;%s\n" % (ssid, password))
with open(NETWORK_PROFILES, "w") as f:
f.write(''.join(lines))
def do_connect(ssid, password):
wlan_sta.active(True)
if wlan_sta.isconnected():
return None
print('Trying to connect to %s...' % ssid)
wlan_sta.connect(ssid, password)
for retry in range(100):
connected = wlan_sta.isconnected()
if connected:
break
time.sleep(0.1)
print('.', end='')
if connected:
print('\nConnected. Network config: ', wlan_sta.ifconfig())
else:
print('\nFailed. Not Connected to: ' + ssid)
return connected
def send_header(client, status_code=200, content_length=None ):
client.sendall("HTTP/1.0 {} OK\r\n".format(status_code))
client.sendall("Content-Type: text/html\r\n")
if content_length is not None:
client.sendall("Content-Length: {}\r\n".format(content_length))
client.sendall("\r\n")
def send_response(client, payload, status_code=200):
content_length = len(payload)
send_header(client, status_code, content_length)
if content_length > 0:
client.sendall(payload)
client.close()
def handle_root(client):
wlan_sta.active(True)
ssids = sorted(ssid.decode('utf-8') for ssid, *_ in wlan_sta.scan())
send_header(client)
client.sendall("""\
<html>
<h1 style="color: #5e9ca0; text-align: center;">
<span style="color: #ff0000;">
Wi-Fi Client Setup
</span>
</h1>
<form action="configure" method="post">
<table style="margin-left: auto; margin-right: auto;">
<tbody>
""")
while len(ssids):
ssid = ssids.pop(0)
client.sendall("""\
<tr>
<td colspan="2">
<input type="radio" name="ssid" value="{0}" />{0}
</td>
</tr>
""".format(ssid))
client.sendall("""\
<tr>
<td>Password:</td>
<td><input name="password" type="password" /></td>
</tr>
</tbody>
</table>
<p style="text-align: center;">
<input type="submit" value="Submit" />
</p>
</form>
<p> </p>
<hr />
<h5>
<span style="color: #ff0000;">
Your ssid and password information will be saved into the
"%(filename)s" file in your ESP module for future usage.
Be careful about security!
</span>
</h5>
<hr />
<h2 style="color: #2e6c80;">
Some useful infos:
</h2>
<ul>
<li>
Original code from <a href="https://github.com/cpopp/MicroPythonSamples"
target="_blank" rel="noopener">cpopp/MicroPythonSamples</a>.
</li>
<li>
This code available at <a href="https://github.com/tayfunulu/WiFiManager"
target="_blank" rel="noopener">tayfunulu/WiFiManager</a>.
</li>
</ul>
</html>
""" % dict(filename=NETWORK_PROFILES))
client.close()
def handle_configure(client, request):
match = ure.search("ssid=([^&]*)&password=(.*)", request)
if match is None:
send_response(client, "Parameters not found", status_code=400)
return False
# version 1.9 compatibility
try:
ssid = match.group(1).decode("utf-8").replace("%3F", "?").replace("%21", "!")
password = match.group(2).decode("utf-8").replace("%3F", "?").replace("%21", "!")
except Exception:
ssid = match.group(1).replace("%3F", "?").replace("%21", "!")
password = match.group(2).replace("%3F", "?").replace("%21", "!")
if len(ssid) == 0:
send_response(client, "SSID must be provided", status_code=400)
return False
if do_connect(ssid, password):
response = """\
<html>
<center>
<br><br>
<h1 style="color: #5e9ca0; text-align: center;">
<span style="color: #ff0000;">
ESP successfully connected to WiFi network %(ssid)s.
</span>
</h1>
<br><br>
</center>
</html>
""" % dict(ssid=ssid)
send_response(client, response)
try:
profiles = read_profiles()
except OSError:
profiles = {}
profiles[ssid] = password
write_profiles(profiles)
time.sleep(5)
return True
else:
response = """\
<html>
<center>
<h1 style="color: #5e9ca0; text-align: center;">
<span style="color: #ff0000;">
ESP could not connect to WiFi network %(ssid)s.
</span>
</h1>
<br><br>
<form>
<input type="button" value="Go back!" onclick="history.back()"></input>
</form>
</center>
</html>
""" % dict(ssid=ssid)
send_response(client, response)
return False
def handle_not_found(client, url):
send_response(client, "Path not found: {}".format(url), status_code=404)
def stop():
global server_socket
if server_socket:
server_socket.close()
server_socket = None
def start(port=80):
global server_socket
addr = socket.getaddrinfo('0.0.0.0', port)[0][-1]
stop()
wlan_sta.active(True)
wlan_ap.active(True)
wlan_ap.config(essid=ap_ssid, password=ap_password, authmode=ap_authmode)
server_socket = socket.socket()
server_socket.bind(addr)
server_socket.listen(1)
print('Connect to WiFi ssid ' + ap_ssid + ', default password: ' + ap_password)
print('and access the ESP via your favorite web browser at 192.168.4.1.')
print('Listening on:', addr)
while True:
if wlan_sta.isconnected():
return True
client, addr = server_socket.accept()
print('client connected from', addr)
try:
client.settimeout(5.0)
request = b""
try:
while "\r\n\r\n" not in request:
request += client.recv(512)
except OSError:
pass
print("Request is: {}".format(request))
if "HTTP" not in request: # skip invalid requests
continue
# version 1.9 compatibility
try:
url = ure.search("(?:GET|POST) /(.*?)(?:\\?.*?)? HTTP", request).group(1).decode("utf-8").rstrip("/")
except Exception:
url = ure.search("(?:GET|POST) /(.*?)(?:\\?.*?)? HTTP", request).group(1).rstrip("/")
print("URL is {}".format(url))
if url == "":
handle_root(client)
elif url == "configure":
handle_configure(client, request)
else:
handle_not_found(client, url)
finally:
client.close()
main.py
import wifimgr
wlan = wifimgr.get_connection()
if wlan is None:
print("Could not initialize the network connection.")
while True:
pass # you shall not pass :D
# Main Code goes here, wlan is a working network.WLAN(STA_IF) instance.
print("ESP OK")
更新
import network
import socket
import ure
import time
ap_ssid = "upday"
ap_password = "12345678"
ap_authmode = 3 # WPA2
NETWORK_PROFILES = 'wifi.dat'
wlan_ap = network.WLAN(network.AP_IF)
wlan_sta = network.WLAN(network.STA_IF)
server_socket = None
def get_connection():
"""return a working WLAN(STA_IF) instance or None"""
# First check if there already is any connection:
if wlan_sta.isconnected():
return wlan_sta
connected = False
try:
# ESP connecting to WiFi takes time, wait a bit and try again:
time.sleep(3)
if wlan_sta.isconnected():
return wlan_sta
# Read known network profiles from file
profiles = read_profiles()
# Search WiFis in range
wlan_sta.active(True)
networks = wlan_sta.scan()
AUTHMODE = {0: "open", 1: "WEP", 2: "WPA-PSK", 3: "WPA2-PSK", 4: "WPA/WPA2-PSK"}
for ssid, bssid, channel, rssi, authmode, hidden in sorted(networks, key=lambda x: x[3], reverse=True):
ssid = ssid.decode('utf-8')
encrypted = authmode > 0
print("ssid: %s chan: %d rssi: %d authmode: %s" % (ssid, channel, rssi, AUTHMODE.get(authmode, '?')))
if encrypted:
if ssid in profiles:
password = profiles[ssid]
connected = do_connect(ssid, password)
else:
print("skipping unknown encrypted network")
else: # open
connected = do_connect(ssid, None)
if connected:
break
except OSError as e:
print("exception", str(e))
# start web server for connection manager:
if not connected:
connected = start()
return wlan_sta if connected else None
def read_profiles():
with open(NETWORK_PROFILES) as f:
lines = f.readlines()
profiles = {}
for line in lines:
ssid, password = line.strip("\n").split(";")
profiles[ssid] = password
return profiles
def write_profiles(profiles):
lines = []
for ssid, password in profiles.items():
lines.append("%s;%s\n" % (ssid, password))
with open(NETWORK_PROFILES, "w") as f:
f.write(''.join(lines))
def do_connect(ssid, password):
wlan_sta.active(True)
if wlan_sta.isconnected():
return None
print('Trying to connect to %s...' % ssid)
wlan_sta.connect(ssid, password)
for retry in range(100):
connected = wlan_sta.isconnected()
if connected:
break
time.sleep(0.1)
print('.', end='')
if connected:
print('\nConnected. Network config: ', wlan_sta.ifconfig())
else:
print('\nFailed. Not Connected to: ' + ssid)
return connected
def send_header(client, status_code=200, content_length=None ):
client.sendall("HTTP/1.0 {} OK\r\n".format(status_code))
client.sendall("Content-Type: text/html\r\n")
if content_length is not None:
client.sendall("Content-Length: {}\r\n".format(content_length))
client.sendall("\r\n")
def send_response(client, payload, status_code=200):
content_length = len(payload)
send_header(client, status_code, content_length)
if content_length > 0:
client.sendall(payload)
client.close()
def handle_root(client):
wlan_sta.active(True)
ssids = sorted(ssid.decode('utf-8') for ssid, *_ in wlan_sta.scan())
send_header(client)
client.sendall("""\
<html>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<head>
<h2 style="color: #5e9ca0; text-align: center;">
<span style="color: #ff0000;">
请选择浇灌系统连接的wifi热点
</span>
</h2>
<form action="configure" method="post">
<table style="margin-left: auto; margin-right: auto;">
<tbody>
""")
while len(ssids):
ssid = ssids.pop(0)
client.sendall("""\
<tr>
<td colspan="2">
<input type="radio" name="ssid" value="{0}" />{0}
</td>
</tr>
""".format(ssid))
client.sendall("""\
<tr>
<td>密码:</td>
<td><input name="password" type="password" /></td>
</tr>
</tbody>
</table>
<p style="text-align: center;">
<input type="submit" value="提交" />
</p>
</form>
<p> </p>
<hr />
<h4>
<span style="color: #ff0000;">
设置成功后,请断开电源重新通电。
</span>
</h4>
<hr />
<h3 style="color: #2e6c80;">
使用参考:
</h3>
<ul>
<li>
请访问 <a href="https://up.day"
target="_blank" rel="noopener">up.day</a>.
</li>
</ul>
</html>
""" )
client.close()
def handle_configure(client, request):
match = ure.search("ssid=([^&]*)&password=(.*)", request)
if match is None:
send_response(client, "Parameters not found", status_code=400)
return False
# version 1.9 compatibility
try:
ssid = match.group(1).decode("utf-8").replace("%3F", "?").replace("%21", "!")
password = match.group(2).decode("utf-8").replace("%3F", "?").replace("%21", "!")
except Exception:
ssid = match.group(1).replace("%3F", "?").replace("%21", "!")
password = match.group(2).replace("%3F", "?").replace("%21", "!")
if len(ssid) == 0:
send_response(client, "SSID must be provided", status_code=400)
return False
if do_connect(ssid, password):
response = """\
<html>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<head>
<center>
<br><br>
<h1 style="color: #5e9ca0; text-align: center;">
<span style="color: #ff0000;">
成功连接到 WiFi 网络 %(ssid)s,请断电重启.
</span>
</h1>
<br><br>
</center>
</html>
""" % dict(ssid=ssid)
send_response(client, response)
try:
profiles = read_profiles()
except OSError:
profiles = {}
profiles[ssid] = password
write_profiles(profiles)
time.sleep(5)
return True
else:
response = """\
<html>
<center>
<h1 style="color: #5e9ca0; text-align: center;">
<span style="color: #ff0000;">
ESP could not connect to WiFi network %(ssid)s.
</span>
</h1>
<br><br>
<form>
<input type="button" value="Go back!" onclick="history.back()"></input>
</form>
</center>
</html>
""" % dict(ssid=ssid)
send_response(client, response)
return False
def handle_not_found(client, url):
send_response(client, "Path not found: {}".format(url), status_code=404)
def stop():
global server_socket
if server_socket:
server_socket.close()
server_socket = None
def start(port=80):
global server_socket
addr = socket.getaddrinfo('0.0.0.0', port)[0][-1]
stop()
wlan_sta.active(True)
wlan_ap.active(True)
wlan_ap.config(essid=ap_ssid, password=ap_password, authmode=ap_authmode)
server_socket = socket.socket()
server_socket.bind(addr)
server_socket.listen(1)
print('Connect to WiFi ssid ' + ap_ssid + ', default password: ' + ap_password)
print('and access the ESP via your favorite web browser at 192.168.4.1.')
print('Listening on:', addr)
while True:
if wlan_sta.isconnected():
return True
client, addr = server_socket.accept()
print('client connected from', addr)
try:
client.settimeout(5.0)
request = b""
try:
while "\r\n\r\n" not in request:
request += client.recv(512)
except OSError:
pass
print("Request is: {}".format(request))
if "HTTP" not in request: # skip invalid requests
continue
# version 1.9 compatibility
try:
url = ure.search("(?:GET|POST) /(.*?)(?:\\?.*?)? HTTP", request).group(1).decode("utf-8").rstrip("/")
except Exception:
url = ure.search("(?:GET|POST) /(.*?)(?:\\?.*?)? HTTP", request).group(1).rstrip("/")
print("URL is {}".format(url))
if url == "":
handle_root(client)
elif url == "configure":
handle_configure(client, request)
else:
handle_not_found(client, url)
finally:
client.close()
另一个详细参考
https://blog.csdn.net/weixin_37272286/article/details/116297086
编译esp32-c3的micropython固件
1.1.2. ESP-IDF开发环境
在linux子系统命令行模式下依次执行如下指令:
cd ~
git clone https://gitee.com/EspressifSystems/esp-gitee-tools.git
git clone https://gitee.com/EspressifSystems/esp-idf.git
ls
cd esp-idf
git checkout v4.4.1
cd ~/esp-gitee-tools
./submodule-update.sh ~/esp-idf/
./install.sh ~/esp-idf/
. /home/peter/esp-idf/export.sh
idf.py build
cd ~/esp-idf/
source export.sh
cd ~
git clone https://gitee.com/CHN_ZC/micropython.git
sudo chmod a+rwx micropython
cd ~/micropython
make -C mpy-cross
cd ports/esp32
make submodules
make
1.1.4. 测试模块
Python文件模块放在esp32下的modules文件夹,进入该文件夹:
cd modules
新建一个测试用的python文件,如下:
nano test.py
文件内容如下:
from time import sleep
def hello():
print("hello world")
def hw(str):
print(str)
def cycle(str):
while True:
print(str)
sleep(1)保存后回到esp32目录,执行编译操作:
cd ~/micropython #micropython根目录
make -C mpy-cross
cd ports/esp32/
. /home/peter/esp-idf/export.sh编译esp32c3固件
make clean
更改ports/esp32/Makefile文件
找到 BOARD ?= GENERIC
改为 BOARD ?= GENERIC_C3
或
BOARD ?= GENERIC_C3_USBmake
留意上面的三个文件及地址,分别是烧录文件及偏移地址。
注意:
严格按照执行后的提示执行一下,否则会导致环境变量等等没有设置,为后续编译带来很多麻烦
esptool安装方法
1. 下载 esptool.py 源码
git clone https://github.com/espressif/esptool.git
2. 目录导入到全局环境变量
以 ubuntu 为例:
将 export PATH=/home/chenwu/esp/esptool:$PATH 添加到 /etc/profile 文件结尾
执行 source /etc/profile
3.安装成功后通过 esptool.py version 查看版本:
注意: esptool.py v3.0 版本后,才对 ESP32-S 系列支持。
如果使用新款芯片,可以通过 git pull 来更新 esptool.py 版本。
关于luatos的esp32-c3的烧录注意事项(USB-JTAG)
1、按住rst键不放,再按住boot键不放,此时松开rst键
2、esptool.py –chip esp32c3 –port /dev/ttyACM1 erase_flash
3、正常烧录固件
4、按下rst键盘重启
5、正常使用
密码保护:智能浇灌程序
树莓派系列配置屏幕常亮、去掉启动滚动代码及彩虹画,增加开机动画
1 设置不黑屏不休眠
1.1 打开lightdm.conf
sudo nano /etc/lightdm/lightdm.conf
1.
1.2 修改lightdm.conf
找到 [SeatDefaults] 段下的 ’xserver-command=X’, 取消注释 , 修改为
xserver-command=X -s 0 -dpms
-s 设置屏幕保护不启用
dpms 关闭电源节能管理
1.3 重启使设置生效
sudo reboot
1.
2 屏蔽开机彩虹屏和文本,修改开机启动图片、设置开机动画
2.1 硬件环境
树莓派4B
系统:Linux raspberrypi 5.10.63-v7l+ #1496 SMP Wed Dec 1 15:58:56 GMT 2021 armv7l GNU/Linux
2.2 禁用彩虹屏
2.2.1 打开config.txt文件
sudo nano /boot/config.txt
1.
在末尾另起一行输入
disable_splash=1
1.
2.3 取消光标跳动和代码滚动
2.3.1 打开cmdline
sudo nano /boot/cmdline.txt
1.
2.3.2 添加如下命令
consoleblank=1 logo.nologo quiet loglevel=0 plymouth.enable=0 vt.global_cursor_default=0 plymouth.ignore-serial-consoles splash fastboot noatime nodiratime noram
1.
2.4 修改开机启动图片
默认的启动图片是树莓派标识,且树莓派的默认主题是pix(起码我的是这样,不清楚的可以自己查下设备的主题)。所以我的开机图片路径在/usr/share/plymouth/themes/pix/splash.png,把这张图片强覆盖即可。
2.5 添加开机动画
使用开机动画,需要用的一个播放器omxplayer,自行安装
sudo apt-get update
sudo apt-get install omxplayer
1.
2.
2.5.1 打开rc.local文件
sudo nano /etc/rc.local
1.
2.5.2 在适当位置加入命令
omxplayer [动画文件.mov] &
1.
例如我的开机动画视频是logo.mov,放在/home/pi下,那么语句就是
登录后复制
omxplayer /home/pi/logo.mov &
1.
在线图像文件矢量化转换工具
编译micropython-lvgl
屏和esp32引脚接线重新定义:
https://github.com/lvgl/lv_binding_micropython
去除Envo Storefront主题的底部版权信息
今天发现一个wordpress的主题不错,风格超赞,但底部的“自豪地采用wordprss及Envo Storefront”极其刺眼,到网上找了一圈,没有看到去除的方法,于是自己动手,发现这个主题厂家很鬼,将版权信息放在了一个特殊的地方,修改如下:
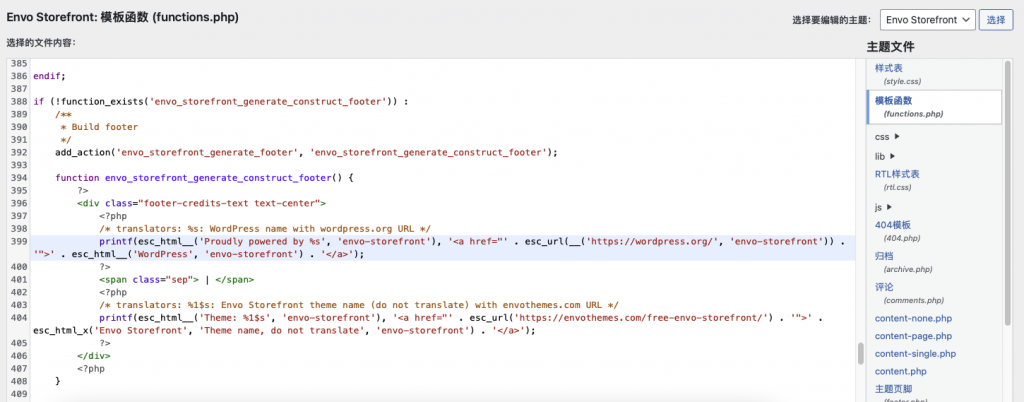
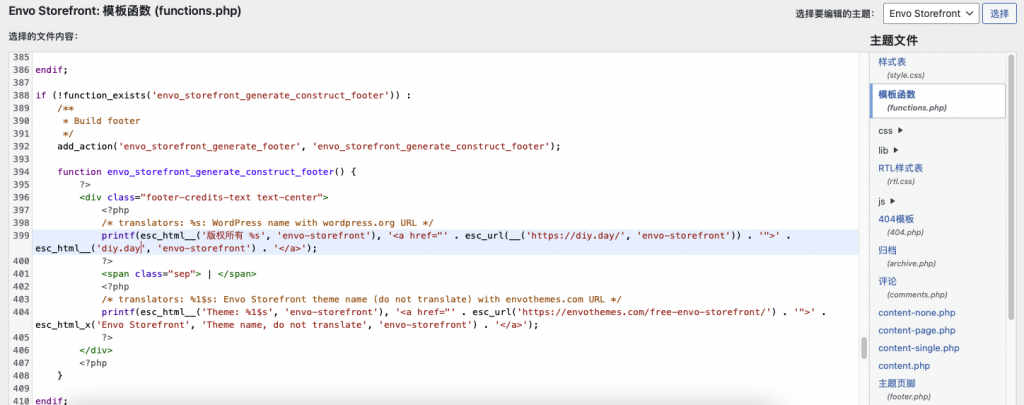
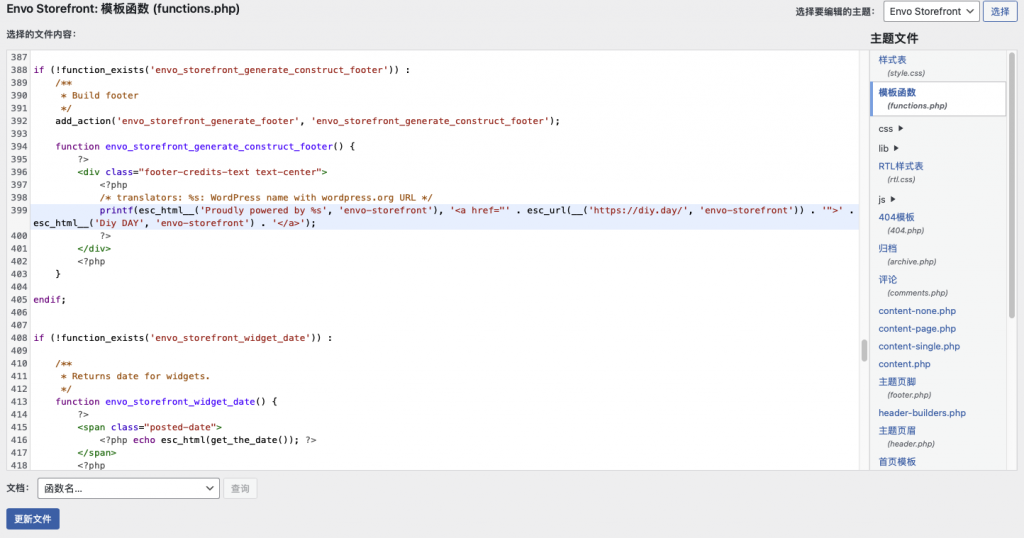
编译esp32-c3 lv-micropython固件
git clone -b v4.3.1 --recursive https://github.com/espressif/esp-idf.git
$ cd esp-idf
$ git checkout v4.3.1
$ git submodule update --init --recursive
$ cd esp-idf
$ ./install.sh # (or install.bat on Windows)
$ source export.sh # (or export.bat on Windows)
$ git clone https://github.com/lvgl/lv_micropython.git
$ cd ~/lv_micropython
$ git submodule update --init
$ cd lib/lv_bindings/
$ git submodule update --init
$ cd ~/lv_micropython/
$ make -C mpy-cross
对于编译过程中缺少的文件,find / -name xxxx,然后拷贝即可,估计是路径设置问题导致编译esp32-c3 micropython lvgl
https://blog.csdn.net/qq_34440409/article/details/118365689
https://blog.csdn.net/wangyx1234/article/details/108554228
git clone https://github.com/lvgl/lv_micropython.git
cd lv_micropython
git submodule update --init
cd lib/lv_bindings/
git submodule update --init编译mpy-cross工具:
cd ~/lv_micropython
make -C mpy-cross编译unix端口的mpy:
make -C ports/unix/编译好后测试下
./ports/unix/micropython重新编译mpy:
cd lv_micropython/ports/unix
make clean
make -jDemo测试
lvgl官方提供的测试例子在这个路径下:lib\lv_bindings\examples
可以用编译出来的micropython解释器去执行该目录下的测试脚本。
举个栗子:
打开/lib/lv_bindings/examples/advanced_demo.py文件,在末尾加入以下代码:
if __name__ == '__main__':
import time
while True:
time.sleep(1)执行
./ports/unix/micropython lib/lv_bindings/examples/advanced_demo.py编译esp32-c3
make -C mpy-cross
make -C ports/esp32 LV_CFLAGS="-DLV_COLOR_DEPTH=16 -DLV_COLOR_16_SWAP=1" BOARD=GENERIC_SPIRAM deployMicroPython端口到ESP32
这是 MicroPython 到乐鑫 ESP32 系列微控制器的端口。它使用ESP-IDF框架,MicroPython在FreeRTOS下作为任务运行。
支持的功能包括:
- REPL(Python prompt)over UART0。
- MicroPython任务的16k堆栈和大约100k的Python堆。
- 启用了MicroPython的许多功能:unicode,任意精度整数,单精度浮点数,复数,冻结字节码以及许多内部模块。
- 使用闪存的内部文件系统(目前大小为2M)。
- 机器模块带有GPIO,UART,SPI,软件I2C,ADC,DAC,PWM,触摸板,WDT和定时器。
- 支持无线局域网 (WiFi) 的网络模块。
- 通过蓝牙模块支持低功耗蓝牙 (BLE)。
该 ESP32 端口的初始开发部分由 Microbric Pty Ltd 赞助。
设置 ESP-IDF 和构建环境
ESP32 上的 MicroPython 需要乐鑫 IDF 版本 4(物联网开发框架,又名 SDK)。ESP-IDF 包括管理 ESP32 微控制器所需的库和 RTOS,以及管理构建固件所需的构建环境和工具链的方法。
ESP-IDF 变化很快,MicroPython 仅支持某些版本。目前,MicroPython 支持 v4.0.2、v4.1.1 和 v4.2,但其他 IDF v4 版本也可能有效。
要安装 ESP-IDF,可在乐鑫入门指南中找到完整说明。
如果您使用的是 Windows 机器,那么适用于 Linux 的 Windows 子系统是安装 ESP32 工具链和构建项目的最有效方法。如果您使用 WSL,请按照 Linux 说明而不是 Windows 说明进行操作。
乐鑫说明将指导您使用(或)脚本下载工具链并设置环境。要采取的步骤总结如下。install.shinstall.bat
要签出 IDF 的副本,请使用 git 克隆:
$ git clone -b v4.0.2 --recursive https://github.com/espressif/esp-idf.git
您可以替换为 或或任何其他受支持的版本。(您不需要完整的递归克隆;有关更详细的设置命令,请参阅此存储库中的函数。v4.0.2v4.1.1v4.2ci_esp32_setuptools/ci.sh
如果您已经拥有 IDF 的副本,请签出与 MicroPython 兼容的版本,并使用以下命令更新子模块:
$ cd esp-idf $ git checkout v4.2 $ git submodule update --init --recursive
克隆 IDF 并将其签出为正确版本后,运行以下脚本:install.sh
$ cd esp-idf $ ./install.sh # (or install.bat on Windows) $ source export.sh # (or export.bat on Windows)
该步骤只需执行一次。您将需要为每个新会话提供源。install.shexport.sh
注意:如果您正在为 ESP32-S2、ESP32-C3 或 ESP32-S3 构建 MicroPython,请确保您使用的是以下必需的 IDF 版本:
- ESP32-S3 目前需要最新的 ,但最终或更晚可用时需要。
masterv4.4 - ESP32-S2 和 ESP32-C3 需要或更高版本。
v4.3.1
构建固件
必须构建MicroPython交叉编译器以将某些内置脚本预编译为字节码。这可以通过以下方式完成(从此存储库的根目录):
$ git clone https://github.com/lvgl/lv_micropython.git $ cd lv_micropython $ git submodule update --init $ cd lib/lv_bindings/ $ git submodule update --init $ cd ~/lv_micropython $ make -C mpy-cross
然后为 ESP32 运行构建 MicroPython:
$ cd ports/esp32 $ make submodules $ make
这将在子目录中生成一个组合映像(此固件映像由以下部分组成:引导加载程序.bin、分区.bin和 micropython.bin)。firmware.binbuild-GENERIC/
要刷新固件,您必须将 ESP32 模块置于引导加载程序模式并连接到 PC 上的串行端口。有关如何执行此操作,请参阅特定 ESP32 模块的文档。您还需要具有用户权限才能访问设备。在 Linux 上,您可以通过将用户添加到组,然后重新启动或注销并再次登录来启用此功能。(注意:在某些发行版上,这可能是组,请运行以检查。/dev/ttyUSB0dialoutuucpls -la /dev/ttyUSB0
$ sudo adduser <username> dialout
如果您是首次将MicroPython安装到您的模块中,或者在安装任何其他固件之后,您应该首先完全擦除闪存:
$ make erase
要将 MicroPython 固件刷新到 ESP32,请使用:
$ make deploy
由上述命令构建的默认 ESP32 开发板是该版本,它应该适用于大多数 ESP32 模块。您可以通过传递给 make 命令来指定不同的电路板,例如:GENERICBOARD=<board>
$ make BOARD=GENERIC_SPIRAM
注意:上述“make”命令是作为 ESP-IDF 一部分的基础构建工具的精简包装器。您可以改为直接使用,例如:idf.pyidf.py
$ idf.py build $ idf.py -D MICROPY_BOARD=GENERIC_SPIRAM build $ idf.py flash
在设备上获取 Python 提示
您可以通过串行端口UART0获得提示,UART0与用于对固件进行编程的UART相同。REPL 的波特率为 115200,您可以使用如下命令:
$ picocom -b 115200 /dev/ttyUSB0
或
$ miniterm.py /dev/ttyUSB0 115200
您还可以使用 .idf.py monitor
配置无线网络和使用开发板
ESP32 端口在模块和面向用户的 API 方面(几乎)等同于 ESP8266。有一些小的区别,特别是 ESP32 在启动时不会自动连接到最后一个接入点。但在大多数情况下,ESP8266 的文档和教程应该适用于 ESP32(至少对于已实现的组件)。
有关快速参考,请参阅 http://docs.micropython.org/en/latest/esp8266/esp8266/quickref.html;有关教程,请参阅 http://docs.micropython.org/en/latest/esp8266/esp8266/tutorial/intro.html。
以下功能可用于连接到WiFi接入点(您可以传入自己的SSID和密码,或更改默认值,以便您可以快速呼叫并正常工作):wlan_connect()
def wlan_connect(ssid='MYSSID', password='MYPASS'):
import network
wlan = network.WLAN(network.STA_IF)
if not wlan.active() or not wlan.isconnected():
wlan.active(True)
print('connecting to:', ssid)
wlan.connect(ssid, password)
while not wlan.isconnected():
pass
print('network config:', wlan.ifconfig())
请注意,某些主板要求您在使用 WiFi 之前配置 WiFi 天线。在像LoPy和WiPy 2.0这样的Pycom板上,你需要执行以下代码来选择内部天线(最好将此行放在 boot.py 文件中):
import machine antenna = machine.Pin(16, machine.Pin.OUT, value=0)
定义自定义 ESP32 开发板
默认的 ESP-IDF 配置设置由目录中的主板定义提供。对于自定义配置,您可以定义自己的主板目录。通过复制现有配置(如)并对其进行修改以适合您的主板来开始新的主板配置。GENERICboards/GENERICGENERIC
特定于 MicroPython 的配置值在特定于主板的文件中定义,该文件包含在 中。其他设置被放入 ,包括配置 ESP-IDF 设置的文件列表。目录中提供了一些标准文件,如 。您还可以在主板目录中定义自定义。mpconfigboard.hmpconfigport.hmpconfigboard.cmakesdkconfigsdkconfigboards/boards/sdkconfig.ble
有关配置的更多示例,请参阅现有主板定义。
配置故障排除
- 编程后连续重启:确保主板正确(例如 ESP-WROOM-32 应为 DIO)。然后执行 、重新生成、重新部署。
CONFIG_ESPTOOLPY_FLASHMODEmake clean
https://github.com/lvgl/lv_micropython
构建说明
Unix (Linux) 端口
sudo apt-get install build-essential libreadline-dev libffi-dev git pkg-config libsdl2-2.0-0 libsdl2-dev python3.8 parallelPython 3 是必需的,但如果需要,您可以安装其他版本的 python3 而不是 3.8。
git clone https://github.com/lvgl/lv_micropython.git
cd lv_micropython
git submodule update --init --recursive lib/lv_bindings
make -C mpy-cross
make -C ports/unix submodules
make -C ports/unix
./ports/unix/micropythonESP32 端口
请为 esp-idf 安装目录设置参数。它需要与Micropython预期的esp-idf匹配,否则将显示警告(并且构建可能会失败)有关更多详细信息,请参阅设置工具链和ESP-IDFESPIDF
使用 IL9341 驱动程序时,需要将颜色深度和交换模式设置为与 ILI9341 匹配。这可以从命令行完成。以下是构建 ESP32 + LVGL 的命令,该命令与 ILI9341 驱动程序兼容:
make -C mpy-cross
make -C ports/esp32 LV_CFLAGS="-DLV_COLOR_DEPTH=16 -DLV_COLOR_16_SWAP=1" BOARD=GENERIC_SPIRAM deploy
关于参数的说明:
LV_CFLAGS用于覆盖颜色深度和交换模式,以实现 ILI9341 兼容性。
LV_COLOR_DEPTH=16如果您计划使用 ILI9341 驱动程序,则需要。
LV_COLOR_16_SWAP=1如果您计划使用纯微孔显示驱动程序,则需要。
BOARD- 我使用带有SPIRAM的WROVER板。您可以从目录中选择其他板。ports/esp32/boards/
deploy- make命令将创建Micropython的ESP32端口,并将尝试通过USB-UART桥部署它。
有关更多详细信息,请参阅 Micropython ESP32 自述文件。
JavaScript 端口
请参阅分支的自述文件:https://github.com/lvgl/lv_micropython/tree/lvgl_javascript_v8#javascript-portlvgl_javascript
树莓派皮库端口
此端口使用 C 模块的 Micropython 基础结构,并且必须提供:USER_C_MODULES
cd ports/rp2
make USER_C_MODULES=../../lv_bindings/bindings.cmake参考
https://blog.csdn.net/qq_36953463/article/details/120378152
更换头文件:
cp /home/peter/micropython-esp32-homekit_ok/components/esp-idf/components/hal/esp32c3/include/hal/gpio_ll.h /home/peter/esp-idf/components/hal/esp32c3/include/hal/gpio_ll.hhttps://github.com/espressif/esp-idf/blob/master/components/soc/esp32/include/soc/i2s_reg.h
重要参考:
https://github.com/bupthl/lv_micropython
分类目录电子爱好者
固件
在fritzing中插入自己的丝印图像
一直以来,fritzing很受欢迎,但因其用户绝大多数为非行业用户,深入应用案例较少,如何在fritzing的PCB中使用自己的logo或文字网上资料很少,这里给出一个比较简单的方法。
1、安装LibreOffice软件,该软件是流行的免费开源办公软件,对标微软办公三件套
2、打开LibreOffice Draw程序,新建文件并插入艺术字,字体和形状根据自己需要修改
3、修改页面属性中的页面大小,适配艺术字长宽大小
4、导出文件格式为svg
5、在fritzing的PCB视图中插入silkscreen image
{kind=link}
{kind=link}
树莓派中nohup 、&、重定向的使用
一、nohup 和 & 使用方法
1.1、 nohup (不挂断)
nohup 是 no hung up 的缩写,意思是不挂断 。
使用 Xshell 等Linux 客户端工具,远程执行 Linux 脚本时,有时候会由于网络问题,导致客户端失去连接,终端断开,脚本运行一半就意外结束了。这种时候,就可以用nohup 指令来运行指令,使脚本可以忽略挂起,仍可继续运行。
nohup 语法格式:
nohup command [arg…]
1
说明:
除了无法进行输入操作(比如输入命令、换行、打空格等) 外 ,
标准输出 保存到 nohup.out文件中。
关闭客户端后,命令仍然会运行,不会挂断。
例如:
执行 nohup sh test.sh 脚本命令后,终端不能接收任何输入,标准输出 会输出到当前目录的nohup.out 文件。即使关闭xshell 退出后,当前session依然继续运行。
1.2、 & (可交互)
& 语法格式:
command [arg…] &
1
说明:
能进行输入操作(比如输入命令、换行、打空格等),即 可进行交互 输入和输出的操作。
标准输出 保存到 nohup.out文件中。
但是 关闭客户端后,程序会就马上停止。
例如:
执行 sh test.sh & 脚本命令后 ,关闭 xshell,脚本程序也立刻停止。
1.3、nohup 和 & 一块使用(不挂断,可交互)
语法格式:
nohup command [arg…] &
1
说明:
能进行输入操作(比如输入命令、换行、打空格等),即 可进行交互 输入和输出的操作,
标准输出 保存到 nohup.out 中,
关闭客户端后命令仍然会运行。
例子:
执行 nohup sh test.sh & 命令后,能进行输入操作,标准输出 的日志写入到 nohup.out 文件,即使关闭xshell,退出当前session后,脚本命令依然继续运行。
输入输出问题已经解决了, 是不是就完美了? 其实还有一个问题没有解决, 请往下看!
二、 日志 的 重定向 >
上面提到的日志文件默认名称是 nohup.out ,如果修改日志文件的名称,则用到 重定向 ,符号是 > ,语法格式是
fileLog
1
说明:是重定向的符号。
fileLog 是日志文件名称,最好是英文、数字。
此时, nohup、 & 、 > 三者一块使用的 语法格式 :
nohup command >fileLog &
1
示例:
nohup start.sh >aa.log &
1
说明:执行上面的命令后,可以进行输入,也能在后台运行,运行的日志输出到 aa.log 日志中。
三、错误信息的处理
nohup command >fileLog &
1
虽然解决输入输出,后台也能运行问题,但是还有一项是 错误信息 无法输出到 日志文件中,要解决这个问题,需要增加命令 2 > file 。
标准输出 和 错误信息 同时使用,语法格式如下:
fileLog1 2 >fileLog2
1
有人会疑问,2 是什么意思? 请往下看。
3.1、Linux 标准输入、输出、错误信息的符号
Linux 标准输入、输出、错误信息的符号:
0 表示 stdin (standard input) 标准信息输入 ;
1 表示 stdout (standard output) 标准信息输出 ;
2 表示 stderr (standard error) 错误信息 ;
/dev/null 表示空设备文件。 如果不想输出任何的日志时,使用此参数 。
再来回顾上面的示例:
fileLog1 2 >fileLog2
1
fileLog1 :即 1 >fileLog1,1是标准信息输出,是默认的,可以省略,fileLog1是 日志文件名字。
2 >fileLog2 :2 是错误信息,即将 错误信息 输出 到 fileLog2 文件中 。
到这时,明白 2 含义了吧!
3.2、错误信息 和 标准输出 输出在同一个文件中
如果想把 错误信息 和 标准输出 在同一个文件中 ,使用 2>&1 。 语法如下:
fileLog 2>&1
1
说明:fileLog 表示 标准信息 输出到 fileLog 文件中;
2>&1 表示 把 2(错误信息) 重定向, 输出到 1(标准输出) 中 。
两者的共同使用,表示 把 2(错误信息) 、1(标准输出) 都输出到同一个文件(fileLog)中。
3.3、思考:不想输出日志信息怎么办 ?
提示:/dev/null 表示空设备文件。 如果不想输出任何的日志时,使用此参数 。
四、综合使用(推荐)
综上所述, 功能最全、推荐语法如下:
nohup command >fileLog 2>&1 &
1
示例:
nohup start.sh > mySysLog.log 2>&1 &
1
说明: 执行命令后,并且将 标准输出(1)、错误信息(2) 写入到 mySysLog.log 文件中。
五、知识扩展
5.1、不停止服务,直接清空nohup.out
如果脚本一直运行下去,nohup.out 日志会一直增长,日志但是硬盘容量有限,怎么把日志文件的大小减少 ?
注意,千万别直接删除日志文件,会造成服务无法输出日志,服务异常直接停止运行,这是最严重生产事故。
不停止服务,直接清空nohup.out文件有两种方法:
第1种:
cat /dev/null > nohup.out
第2种:
cp /dev/null nohup.out
5.2、只记录警告级别比较高的日志
输出的日志太多,nohup.out 增长特别快,对于不重要的日记,可以不记录,选择只记录警告级别比较高的日志。
只输出错误信息到日志文件,其它日志不输出
nohup ./program > /dev/null 2>log &
5.2、不想输出日志
不想输出日志,什么日志都不要,只要服务能正常运行就行了。
什么日志也不输出
nohup ./program > /dev/null 2>&1 &
使用overlayfs打造一个只读的不怕意外关机的树莓派Raspberry Pi
树莓派的本领就不多说了。但是在树莓派的应用场合,关机的时候还是显得尴尬,先不说执行 sudo halt 要么需要ssh上去,要么需要有键盘和显示器,更不要说,有的场景可能连网络和显示器都没有,真正的 headless。 但是如果不执行sudo halt直接关电源,那么有很大的概率会损坏SD卡上的文件系统,甚至损坏SD卡。
overlayfs是linux系统下的一种影子文件系统,它可以把真正的存储文件系统作为只读挂载,而把所有文件改动都存放在RAM中,关机或者重启就失效,真正的保护了存储文件系统。 下面就说一下我在树莓派中实施overlayfs的方法,其实很简单。
我参考了这个帖子中介绍的方法:
https://www.raspberrypi.org/forums/viewtopic.php?t=173063#p1151405
- 首先,禁用交换空间,毕竟树莓派里的交换空间也是占用RAM(tempfs)的,所以如果使用了overlayfs后,交换空间就显得没有意义了。
执行如下3条命令:
sudo dphys-swapfile swapoff
sudo dphys-swapfile uninstall
sudo update-rc.d dphys-swapfile remove
- 更新系统,保证系统为最新状态
sudo apt-get update
sudo apt-get upgrade
- 保存如下脚本为 overlayRoot.sh
注(2020-11-22):如下脚本已过时,最新脚本请前往链接【 http://wiki.psuter.ch/doku.php?id=solve_raspbian_sd_card_corruption_issues_with_read-only_mounted_root_partition#the_script 】
!/bin/sh
Read-only Root-FS for Raspian using overlayfs
Version 1.0
#
Created 2017 by Pascal Suter @ DALCO AG, Switzerland
to work on Raspian as custom init script
(raspbian does not use an initramfs on boot)
#
Modified 2017-Apr-21 by Tony McBeardsley
#
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
#
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
#
You should have received a copy of the GNU General Public License
along with this program. If not, see
http://www.gnu.org/licenses/.
#
#
Tested with Raspbian mini, 2017-01-11
#
This script will mount the root filesystem read-only and overlay it with a temporary tempfs
which is read-write mounted. This is done using the overlayFS which is part of the linux kernel
since version 3.18.
when this script is in use, all changes made to anywhere in the root filesystem mount will be lost
upon reboot of the system. The SD card will only be accessed as read-only drive, which significantly
helps to prolong its life and prevent filesystem coruption in environments where the system is usually
not shut down properly
#
Install:
copy this script to /sbin/overlayRoot.sh and add “init=/sbin/overlayRoot.sh” to the cmdline.txt
file in the raspbian image’s boot partition.
I strongly recommend to disable swapping before using this. it will work with swap but that just does
not make sens as the swap file will be stored in the tempfs which again resides in the ram.
run these commands on the booted raspberry pi BEFORE you set the init=/sbin/overlayRoot.sh boot option:
sudo dphys-swapfile swapoff
sudo dphys-swapfile uninstall
sudo update-rc.d dphys-swapfile remove
#
To install software, run upgrades and do other changes to the raspberry setup, simply remove the init=
entry from the cmdline.txt file and reboot, make the changes, add the init= entry and reboot once more.
fail(){
echo -e “$1”
/bin/bash
}
Load overlay module
modprobe overlay
if [ $? -ne 0 ]; then
fail “ERROR: missing overlay kernel module”
fi
Mount /proc
mount -t proc proc /proc
if [ $? -ne 0 ]; then
fail “ERROR: could not mount proc”
fi
Create a writable fs on /mnt to then create our mountpoints
mount -t tmpfs inittemp /mnt
if [ $? -ne 0 ]; then
fail “ERROR: could not create a temporary filesystem to mount the base filesystems for overlayfs”
fi
Mount a tmpfs under /mnt/rw
mkdir /mnt/rw
mount -t tmpfs root-rw /mnt/rw
if [ $? -ne 0 ]; then
fail “ERROR: could not create tempfs for upper filesystem”
fi
Identify root fs device, PARTUUID, mount options and fs type
rootDev=blkid -o list | awk '$3 == "/" {print $1}'
Changed here(point to / ) in case the cmd above doesn’t work # By ChenYang 20171122
rootDev=/dev/mmcblk0p2
rootPARTUUID=awk '$2 == "/" {print $1}' /etc/fstab
rootMountOpt=awk '$2 == "/" {print $4}' /etc/fstab
rootFsType=awk '$2 == "/" {print $3}' /etc/fstab
Mount original root filesystem readonly under /mnt/lower
mkdir /mnt/lower
mount -t ${rootFsType} -o ${rootMountOpt},ro ${rootDev} /mnt/lower
if [ $? -ne 0 ]; then
fail “ERROR: could not ro-mount original root partition”
fi
Mount the overlay filesystem
mkdir /mnt/rw/upper
mkdir /mnt/rw/work
mkdir /mnt/newroot
mount -t overlay -o lowerdir=/mnt/lower,upperdir=/mnt/rw/upper,workdir=/mnt/rw/work overlayfs-root /mnt/newroot
if [ $? -ne 0 ]; then
fail “ERROR: could not mount overlayFS”
fi
Create mountpoints inside the new root filesystem-overlay
mkdir /mnt/newroot/ro
mkdir /mnt/newroot/rw
Remove root mount from fstab (this is already a non-permanent modification)
grep -v “$rootPARTUUID” /mnt/lower/etc/fstab > /mnt/newroot/etc/fstab
echo “#the original root mount has been removed by overlayRoot.sh” >> /mnt/newroot/etc/fstab
echo “#this is only a temporary modification, the original fstab” >> /mnt/newroot/etc/fstab
echo “#stored on the disk can be found in /ro/etc/fstab” >> /mnt/newroot/etc/fstab
Change to the new overlay root
cd /mnt/newroot
pivot_root . mnt
exec chroot . sh -c “$(cat <<END
# Move ro and rw mounts to the new root
mount --move /mnt/mnt/lower/ /ro
if [ $? -ne 0 ]; then
echo "ERROR: could not move ro-root into newroot"
/bin/bash
fi
mount --move /mnt/mnt/rw /rw
if [ $? -ne 0 ]; then
echo "ERROR: could not move tempfs rw mount into newroot"
/bin/bash
fi
# Unmount unneeded mounts so we can unmout the old readonly root
umount /mnt/mnt
umount /mnt/proc
umount /mnt/dev
umount /mnt
# Continue with regular init
exec /sbin/initEND
)”
注意,我的脚本和帖子里面的有些不同,我把
rootDev=blkid -o list | awk '$3 == "/" {print $1}'
改成了
rootDev=/dev/mmcblk0p2
不改的话,我这里overlayRoot.sh会运行失败
(20180503更新)另外需要注意,如果在Windows下编辑overlayRoot.sh文件,需要保存为Unix文本文档格式,即行结束符为单个LF字符,而不是Windows风格的CR+LR两个字符。否则你可能会看到如下错误:
—[ end Kernel panic – not syncing: Requested init /sbin/overlayRoot.sh failed (error -2).
- 将脚本拷贝到 /sbin/overlayRoot.sh
sudo cp overlayRoot.sh /sbin/overlayRoot.sh
sudo chmod a+x /sbin/overlayRoot.sh
- 修改 cmdline.txt 文件,在行尾加上 “init=/sbin/overlayRoot.sh”,如下是我的 /boot/cmdline.txt 文件的内容
pi@raspberrypi:~ $ cat /boot/cmdline.txt
dwc_otg.lpm_enable=0 console=serial0,115200 console=tty1 root=PARTUUID=0e82c2e4-02 rootfstype=ext4 elevator=deadline fsck.repair=yes rootwait init=/sbin/overlayRoot.sh
- 为了保证整个SD卡都是只读,将 /boot 分区也修改为只读, 修改 fstab 文件,把/boot 对应的行改为ro,我的/etc/fstab文件内容如下
pi@raspberrypi:~ $ cat /etc/fstab
proc /proc proc defaults 0 0
PARTUUID=0e82c2e4-01 /boot vfat defaults,ro 0 2
PARTUUID=0e82c2e4-02 / ext4 defaults,noatime 0 1
- 到这里 sudo reboot 重启,重启后,文件系统就处于影子系统的保护之下了,所有对于文件系统的改动,在重启后都将恢复原状。 用mount命令可以确认overlayfs的正常工作。
root-rw on /rw type tmpfs (rw,relatime)
/dev/mmcblk0p2 on /ro type ext4 (ro,noatime,data=ordered)
overlayfs-root on / type overlay (rw,relatime,lowerdir=/mnt/lower,upperdir=/mnt/rw/upper,workdir=/mnt/rw/work)
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,relatime)
devtmpfs on /dev type devtmpfs (rw,nosuid,size=470160k,nr_inodes=117540,mode=755)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,nodev,mode=755)
tmpfs on /run/lock type tmpfs (rw,nosuid,nodev,noexec,relatime,size=5120k)
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/net_cls type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls)
systemd-1 on /proc/sys/fs/binfmt_misc type autofs (rw,relatime,fd=25,pgrp=1,timeout=0,minproto=5,maxproto=5,direct)
debugfs on /sys/kernel/debug type debugfs (rw,relatime)
sunrpc on /run/rpc_pipefs type rpc_pipefs (rw,relatime)
mqueue on /dev/mqueue type mqueue (rw,relatime)
configfs on /sys/kernel/config type configfs (rw,relatime)
/dev/mmcblk0p1 on /boot type vfat (ro,relatime,fmask=0022,dmask=0022,codepage=437,iocharset=ascii,shortname=mixed,errors=remount-ro)
tmpfs on /run/user/1000 type tmpfs (rw,nosuid,nodev,relatime,size=94952k,mode=700,uid=1000,gid=1000)
原来的根文件系统 /dev/mmcblk0p2 改为挂载在 /ro ,并且是只读;/boot 也挂载为只读;而 / 的 type 变成了overlay。
好了,直接拔电试试看吧。事实上你可以反复尝试不正常关机,都不会有问题。
- 以后如果想禁用overlayfs,可以修改 cmdline.txt 把 “init=/sbin/overlayRoot.sh” 删掉,重启即可。 当然修改前要先把 /boot remount 成可写状态。
更新系统等操作都需要先禁用overlayfs后再执行。
- 如果临时想修改原 /boot 以及根文件系统的内容可以如下命令remount
要remount /boot为可写
pi@raspberrypi:~ $ sudo mount -o remount,rw /boot
原来的根文件系统在overlayfs下是挂载在 /ro 的,要remount的话
pi@raspberrypi:~ $ sudo mount -o remount,rw /ro
注意,remount文件系统为可写后,要重启和关机需要使用sudo reboot或者sudo halt,不可以强行非正常关机,以免损坏文件系统。
PS. 网上有人报告,如果在不接显示器的情况下(即 headless),如上脚本会运行失败,但是我不接显示器时并没有遇到此问题 。
PS2. 网上有另外一个脚本,链接如下
使用了 update-initramfs 的方式,我在官方系统中可以使用,但是在修改了内核的系统中,运行失败。
【20180717后记】
— 如果开启了overlay以后,root分区的所有变动重启后都会丢失,如果要保存数据,可以缩小root分区后另外建立一个分区,使用FAT32,并mount为rw, sync, flush,用来保存数据,另外最好使用f2fs分区格式,据说f2fs就是针对SD卡之类的存储优化设计的。当然保存数据的频率不要太高,否则异常关机仍有可能会损坏SD卡,就失去使用overlay的意义了。 如果保存数据的频率很高,比如log,可以考虑保存到外接U盘。
— 也有人把 /boot 挂载为rw并临时存放数据,我认为那是不可取的,因为 /boot 里面存放的是启动设置信息以及内核等。
— 网上也有人修改脚本,(https://github.com/jacobalberty/root-ro),使得可以短路某GPIO后启动系统就可写,断开后启动就只读。这是个好主意,有空研究一下。
【20180718更新】 另写了一篇来说明上面这一条的方法。 https://blog.csdn.net/zhufu86/article/details/81100710
【20180720更新】 为了方便识别当前系统是不是在overlayfs模式下,我在 .bashrc 的结尾加上如下几行(当然必须在非overlayfs下修改,否则修改内容不会保存),这样如果是在overlayfs模式下,命令提示行的前面会加上“[OVL]”
find_overlay=mount | grep overlay
if [ ${#find_overlay} -gt 0 ]; then
PS1=”[OVL] $PS1″
fi
【2020-11-22更新】最近留意到raspi-config里面已经有了打开Overlay FS的功能,但是我不是很清楚其使用的方案,大概了解了一下,似乎需要动内核相关文件(如果我的认知有误请指正),这个是我不喜欢的。因为有时如果使用定制化内核,就可能和这种方案有冲突。 同时,我发现本文中方案的原作者已经更新了脚本 overlayRoot.sh ,请前往链接【 http://wiki.psuter.ch/doku.php?id=solve_raspbian_sd_card_corruption_issues_with_read-only_mounted_root_partition 】,他解决了之前自动搜索fstab文件中相关分区信息失败的问题。
https://blog.csdn.net/farmanlinuxer/article/details/96880345
树莓派RaspberryPiB+Raspbian-jessie制作只读系统的python3脚本