RPi.GPIO是 Python的一个module( 模块 ), 树莓派官方系统默认已经安装, 仍在不断更新中, 截至20180521, 最新版0.6.3, 适配了树莓派3B+, 可以访问 python主页下载源码 . 本文根据树莓派RPI.GPIO模块的官方文档翻译,当时的模块版本为0.6.3。官方的帮助文档的链接: https://sourceforge.net/p/raspberry-gpio-python/wiki/BasicUsage/。
1、导入模块
要导入RPi.GPIO模块,请执行以下操作:
import RPi.GPIO as GPIO
通过这样做,您可以通过脚本的其余部分将其称为GPIO。
导入模块并检查它是否成功:
try:
import RPi.GPIO as GPIO
except RuntimeError :
print(
"Error importing RPi.GPIO! This is probably because you need superuser privileges. You can achieve this by using 'sudo' to run your script"
)
2、引脚编号
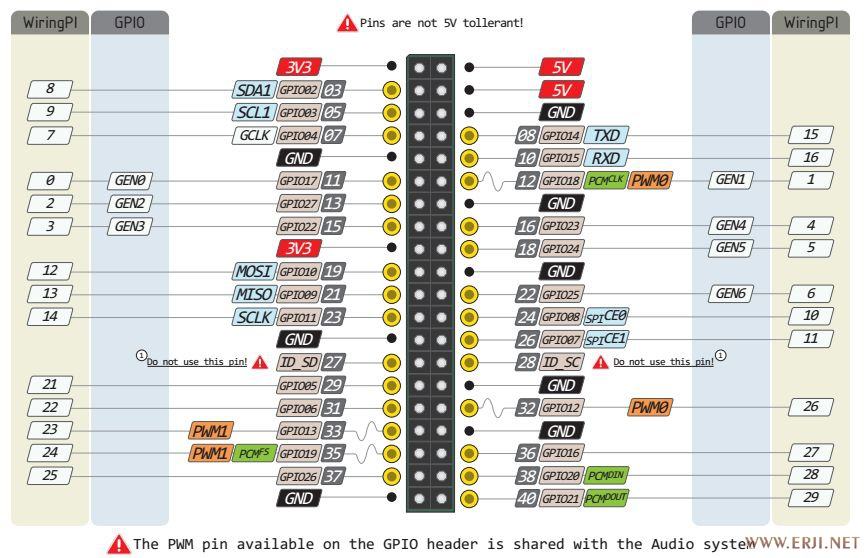
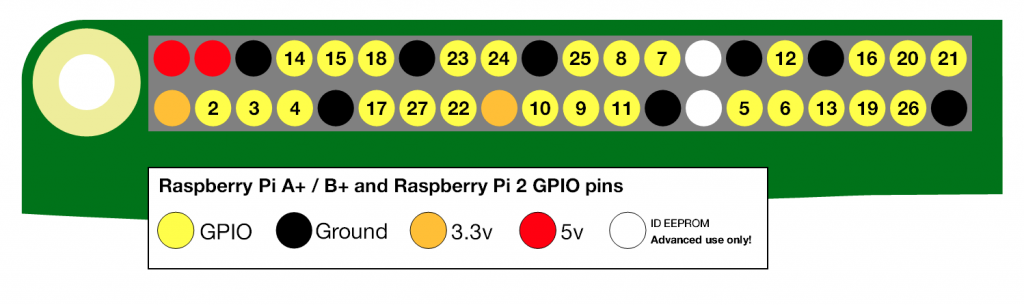
在RPi.GPIO中,有两种方法可以对Raspberry Pi上的IO引脚进行编号。第一种是使用BOARD编号系统。这是指Raspberry Pi板上P1接头上的引脚号。使用这种编号系统的优点是,无论树莓派的电路板版本如何,您的硬件都能正常工作。你不需要重新连接你的连接器或更改你的代码。
第二个编号系统是BCM号码。这是一种较低级别的工作方式 – 它指的是Broadcom SOC上的通道号码。您必须始终使用那个通道编号所对应的树莓派板上哪个引脚的图表。您的脚本程序可能会在Raspberry Pi板的硬件修订后而不能使用。
树莓派引脚有BOARD和BCM两种编号方式( 使用python时? 似乎使用C还有一种wringPi编号方式 ), BOARD具有很好的适用性( 不用看接口图,数引脚1~40就可以接线 ), 不论树莓派1 2 3, 都不用修改代码, 吼啊! BCM编号方式换个版本再接线时数引脚是不行的, 需要看下下面的接口图…不难看出推荐用BOARD编号方式. 但很多程序中使用BCM方式.
下面给出一张树莓派2B的硬件接口图( 来源找不到了,侵删 ):
图中的GPIOxx的方框即是BCM编码方式, 直接写数字的深灰框是BOARD编码方式, 如BCM编码方式的 GPIO02 对应BOARD编码方式的 3.
只需要使用BCM编号方式时, 用下面这两张:
要指定您使用引脚编号方式:
GPIO.setmode(GPIO.BOARD)
# or
GPIO.setmode(GPIO.BCM)
要检测哪个引脚编号系统已被设置模式(例如,由另一个Python模块配置过模式):
mode = GPIO.getmode()
模式将是GPIO.BOARD,GPIO.BCM或None
3、警告
您可能在Raspberry Pi的GPIO上有多个脚本/电路。因此,如果RPi.GPIO检测到引脚已被配置为默认(输入)以外的其他引脚,则在尝试配置脚本时会收到警告。要禁用这些警告:
GPIO.setwarnings(False)
4、设置一个通道
您需要设置您用作输入或输出的每个通道。将通道配置为输入:
GPIO.setup(channel, GPIO.IN)
(其中通道是基于您指定的编号系统(BOARD或BCM)的通道编号)。
有关设置输入通道的更多高级信息可以在这里找到。
要将通道设置为输出:
GPIO.setup(channel, GPIO.OUT)
(其中通道是基于您指定的编号系统(BOARD或BCM)的通道编号)。
您还可以为您的输出通道指定一个初始值:
GPIO.setup(channel, GPIO.OUT, initial=GPIO.HIGH)
4、设置多个频道
您可以一次设置多个通道(从0.5.8开始)。例如:
chan_list = [ 11 ,12 ] #加你想尽可能多的渠道!
#你可以用元组代替,即:
#chan_list =(11,12)
GPIO.setup(chan_list, GPIO.OUT)
5、输入
读取GPIO引脚的值:
GPIO.input(channel)
( 其中通道是基于您指定的编号系统(BOARD或BCM)的通道编号)。这将返回0 / GPIO.LOW / False或1 / GPIO.HIGH / True。
有几种方法可以将GPIO输入到您的程序中。第一种也是最简单的方法是在某个时间点检查输入值。这就是所谓的“轮询”,如果你的程序在错误的时间读取了值,可能会错过输入。轮询在循环中执行,并可能是处理器密集型的。响应GPIO输入的另一种方式是使用’中断’(边沿检测)。边沿是从高电平到低电平(下降沿)或从低电平到高电平(上升沿)的意思。
5.1 上拉/下拉电阻
如果你没有连接到任何输入引脚,它将’浮空’。换句话说,读入的值是未定义的,因为它只有在按下按钮或开关时才会连接到任何东西。由于引脚会接收到干扰,可能读取到变化的值。
为了解决这个问题,我们使用上拉或下拉电阻。这样,可以设置输入的默认值。可以在硬件上使用上拉/下拉电阻并使用软件。在硬件中,通常使用输入通道和3.3V(上拉)或0V(下拉)之间的10K电阻。RPi.GPIO模块允许您配置Broadcom SOC以在软件中执行此操作:
GPIO.setup(channel, GPIO.IN, pull_up_down=GPIO.PUD_UP)
# or
GPIO.setup(channel, GPIO.IN, pull_up_down=GPIO.PUD_DOWN)
(其中通道是基于您指定的编号系统的通道编号 – BOARD或BCM)。
5.2 测试输入(轮询)
您可以立即读取IO引脚的输入值:
if GPIO.input(channel):
print('Input was HIGH')
else:
print('Input was LOW')
要通过轮询轮询等待按钮按下:
while GPIO.input(channel) == GPIO.LOW:
time.sleep(0.01) # wait 10 ms to give CPU chance to do other things
(这里假设按下按钮将输入从LOW改变为HIGH)
5.3 中断和边缘检测
边沿是电信号从低电平变为高电平(上升沿)或从高电平变为低电平(下降沿)的状态变化。很多时候,我们更关心输入状态的变化而非价值。这种状态变化是一个事件。
为了避免在程序忙于做其他事情时按下按钮,有两种方法可以解决这个问题:
- wait_for_edge()函数
- event_detected()函数
- 在检测到边缘时运行线程的回调函数
wait_for_edge()函数
wait_for_edge()函数设计用于阻止程序的执行,直到检测到边缘。换句话说,上面等待按钮按下的示例可以被重写为:
GPIO.wait_for_edge(channel, GPIO.RISING)
请注意,您可以检测GPIO.RISING,GPIO.FALLING或GPIO.BOTH类型的边沿。这样做的好处是它使用的CPU时间可以忽略不计,因此CPU还有很多工作要做。
如果您只想等待一段时间,则可以使用timeout参数:
#上升沿等待最多5秒(超时以毫秒为单位)
channel = GPIO.wait_for_edge(channel, GPIO_RISING, timeout=5000)
if channel is None:
print('Timeout occurred')
else:
print('Edge detected on channel', channel)
event_detected()函数
event_detected()函数设计用于与其他工作一起循环使用,但与轮询不同,在CPU忙于处理其他事情时,不会错过输入状态的变化。当使用类似Pygame或PyQt的东西时,这可能很有用,因为主循环会及时监听和响应GUI事件。
GPIO.add_event_detect(channel, GPIO.RISING) # add rising edge detection on a channel
do_something()
if GPIO.event_detected(channel):
print('Button pressed')
请注意,您可以检测GPIO.RISING,GPIO.FALLING或GPIO.BOTH的事件。
Threaded回调
RPi.GPIO为回调函数运行第二个线程。这意味着回调函数可以与主程序同时运行,并立即响应边缘事件。例如:
def my_callback(channel):
print('This is a edge event callback function!')
print('Edge detected on channel %s'%channel)
print('This is run in a different thread to your main program')
GPIO.add_event_detect(channel, GPIO.RISING, callback=my_callback) # add rising edge detection on a channel
...the rest of your program...
如果你想要多个回调函数:
ef my_callback_one(channel):
print('Callback one')
def my_callback_two(channel):
print('Callback two')
GPIO.add_event_detect(channel, GPIO.RISING)
GPIO.add_event_callback(channel, my_callback_one)
GPIO.add_event_callback(channel, my_callback_two)
请注意,在这种情况下,回调函数按顺序运行,而不是同时运行。这是因为只有一个线程用于回调,每个回调都按照定义的顺序运行。
5.4开关抖动
您可能会注意到,每次按下按钮都会多次调用回调。这是所谓的“开关抖动”的结果。处理抖动有两种方法:
- 在开关输入脚上添加一个0.1uF的电容。
- 软件去除抖动
- 以上两种方法的结合
要使用软件去抖动,请将bouncetime =参数添加到指定回调函数的函数中。抖动时间应以毫秒为单位指定。例如:
#在通道上添加上升沿检测,忽略处理
GPIO的开关抖动操作的进一步边缘200ms 。
GPIO.add_event_detect(channel, GPIO.RISING, callback=my_callback, bouncetime=200)
要么
GPIO.add_event_callback(channel, my_callback, bouncetime=200)
5.5 删除事件检测
如果由于某种原因,您的程序不再希望检测边缘事件,则可以删除它们:
GPIO.remove_event_detect(channel)
6、输出
要设置GPIO引脚的输出状态,请执行以下操作:
GPIO.output(channel, state)
(其中通道是基于您指定的编号系统(BOARD或BCM)的通道编号)。
状态可以是0 / GPIO.LOW / False或1 / GPIO.HIGH / True。
A.设置输出高电平:
GPIO.output(12, GPIO.HIGH)
# or
GPIO.output(12, 1)
# or
GPIO.output(12, True)
B.设置输出低电平:
GPIO.output(12, GPIO.LOW)
# or
GPIO.output(12, 0)
# or
GPIO.output(12, False)
7、输出到几个通道
您可以一次设置输出多个频道(从0.5.8开始)。例如:
chan_list = [11,12] # also works with tuples
GPIO.output(chan_list, GPIO.LOW) # sets all to GPIO.LOW
GPIO.output(chan_list, (GPIO.HIGH, GPIO.LOW)) # sets first HIGH and second LOW
8.在RPi.GPIO中使用PWM
要创建一个PWM实例:
p = GPIO.PWM(channel, frequency)
要启动PWM:
p.start(dc) # where dc is the duty cycle (0.0 <= dc <= 100.0)
要更改频率:
p 。ChangeFrequency (freq ) #其中freq是以Hz为单位的新频率
要改变占空比:
p.ChangeDutyCycle(dc) # where 0.0 <= dc <= 100.0
要停止PWM:
p.stop()
请注意,如果实例变量’p’超出范围,PWM也会停止。
每两秒闪烁一次LED的示例:
import RPi.GPIO as GPIO
GPIO.setmode(GPIO.BOARD)
GPIO.setup(12, GPIO.OUT)
p = GPIO.PWM(12, 0.5)
p.start(1)
input('Press return to stop:') # use raw_input for Python 2
p.stop()
GPIO.cleanup()
增亮/调暗LED的示例:
import time
import RPi.GPIO as GPIO
GPIO.setmode(GPIO.BOARD)
GPIO.setup(12, GPIO.OUT)
p = GPIO.PWM(12, 50) # channel=12 frequency=50Hz
p.start(0)
try:
while 1:
for dc in range(0, 101, 5):
p.ChangeDutyCycle(dc)
time.sleep(0.1)
for dc in range(100, -1, -5):
p.ChangeDutyCycle(dc)
time.sleep(0.1)
except KeyboardInterrupt:
pass
p.stop()
GPIO.cleanup()
9、GPIO恢复默认
在程序的末尾,清理您可能使用的任何资源是一种很好的做法。这与RPi.GPIO没有什么不同。通过将您用过的所使用的通道返回到到无上拉/下拉输入的状态,这样可以避免短接GPIO引脚来导致意外损坏您的树莓派。请注意,这样只会清除你写的脚本中使用的GPIO通道。请注意,GPIO.cleanup()也会清除正在使用的引脚编号系统。
在你的脚本程序的末尾写上:
GPIO.cleanup()
当您的程序退出时,可能不希望清理每个通道,而留下一些设置。您可以清理个别通道,使用通道的元组或列表做为参数输入:
GPIO.cleanup(channel)
GPIO.cleanup( (channel1, channel2) )
GPIO.cleanup( [channel1, channel2] )
10、RPi板信息和RPi.GPIO版本
发现有关您的RPi的信息:
GPIO.RPI_INFO
发现Raspberry Pi电路板版本:
GPIO.RPI_INFO [ 'P1_REVISION']
GPIO.RPI_REVISION(不建议使用)
要发现RPi.GPIO的版本:
GPIO.VERSION
 11、编写一个测试程序blinkled.py
11、编写一个测试程序blinkled.py
这个测试程序控制树莓派上一GPIO 25每2秒变化一个电平,如果接一个LED灯到这个IO上面,就会看到这个灯亮2秒灭2秒。
#!/usr/bin/python#*coding:utf-8*#GPIO控制LED灯程序import RPi.GPIO as GPIOimport timepin = 25GPIO.setmode(GPIO.BCM)GPIO.setup(pin, GPIO.OUT) while True: GPIO.output(pin, GPIO.HIGH) time.sleep(2) GPIO.output(pin, GPIO.LOW) time.sleep(2)
在这个blinkled.py的目录中,在命令行中执行sudo python blinkled.py就可以运行此程序,LED就会一闪一闪的了