

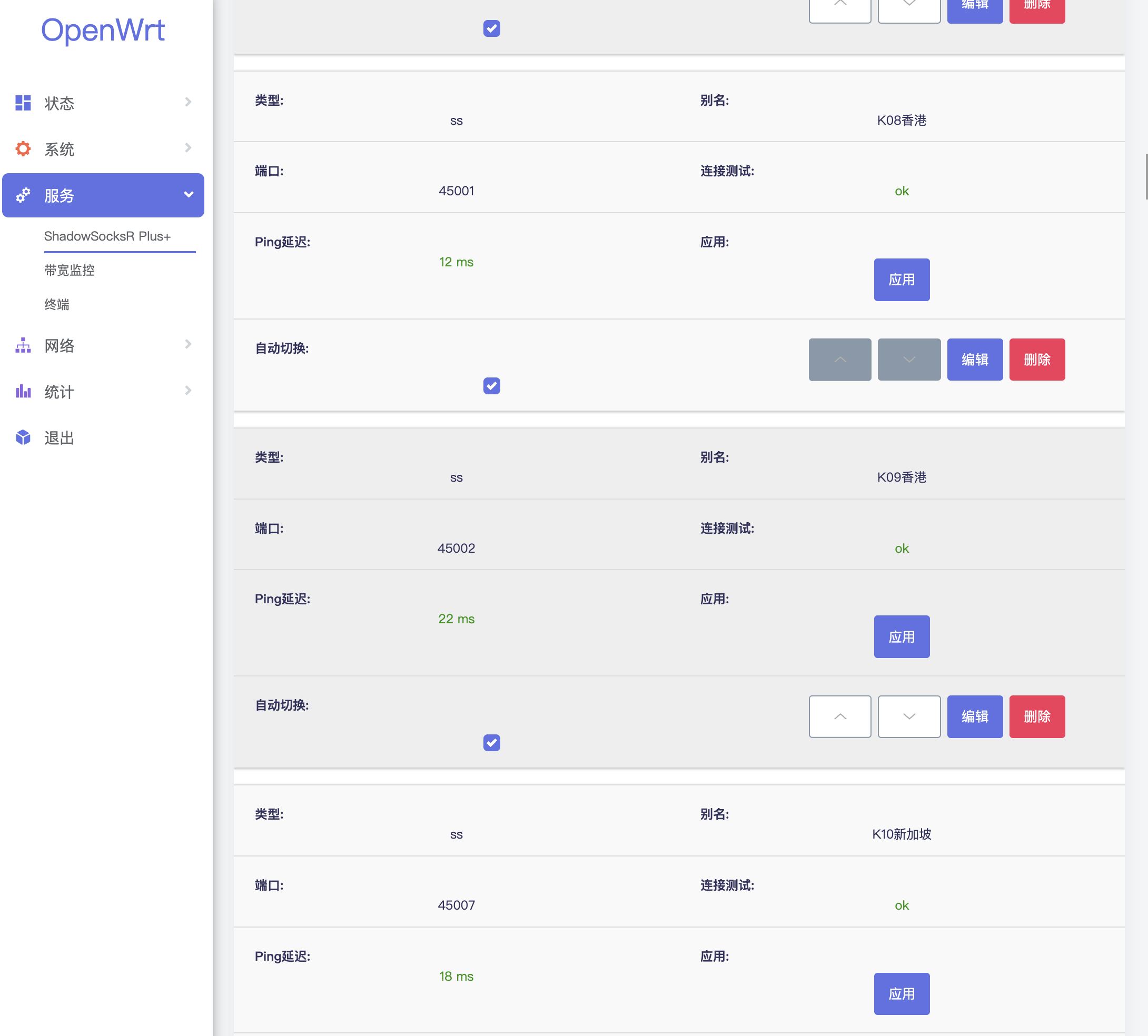
https://docs.exaloop.io/codon/advanced/gpu
sudo cp /home/zjg/libpython3.9.so /usr/lib/libpython.so
在树莓派上安装和配置sendmail,搭建自己的邮件服务器
对于绑定自定义域名的邮箱,需要在域名解析里面增加mx记录,注意:记录值要填写已经解析过的地址,具体如下:


安装sendmail
sudo apt install -y install sendmail sendmail-cf
sendmail的smtp认证配置(不需要认证的可滤过)
设置sendmail服务的网络访问权限
DAEMON_OPTIONS(`Port=smtp,Addr=127.0.0.1, Name=MTA')dnl
改为
DAEMON_OPTIONS(`Port=smtp,Addr=0.0.0.0, Name=MTA')dnl
生成sendmail配置文件
m4 /etc/mail/sendmail.mc > /etc/mail/sendmail.cf #需在root权限下
添加域名
sudo nano /etc/mail/local-host-names #添加 buryin.com
修改submit.cf文件
sudo nano /etc/mail/submit.cf
找到行 #Dj$w.Foo.COM,修改为
Djburyin.com
重启服务使能已配置参数
sudo service sendmail restart
测试一下邮件发送
echo “这是树莓派的sendmail测试” | mail -s 测试 [email protected]
其它可参数配置
centos安装sendmail服务及设置【亲测好用!】_Gavin Matthew的博客-CSDN博客_centos sendmail
sudo apt install dnsutils -y
以打包codon为例 mkdir codon && cd codon mkdir DEBIAN usr && cd usr && mkdir bin cd DEBIAN nano control Package: codon Version: 1.0.0 Architecture: arm64 Maintainer: jack Secion: utils Priority: optional Installed_Size: #可以空白 Description: codon package #此处要空一行 sudo dpkg -b codon dpkg-name codon.deb #改名 sudo dpkg -i codon_1.0.0_arm64.deb #安装 sudo dpkg -r codon #卸载,或者sudo dpkg -P codon 注意: 打包过程中,执行文件放入bin目录,usr的lib目录下放入so文件,同时在usr下拷贝stdlib目录
https://docs.exaloop.io/codon/advanced/build
http://cloud.buryin.com/wp-content/uploads/2022/12/codon-develop-2.zip
编译需要大量的交换空间,否则容易出错,因此先增加交换空间
sudo dd if=/dev/zero of=/swapfile bs=1G count=6 #count的大小就是增加的swap空间的大小,1G是块大小为1G,所以空间大小是bs*count=6G sudo mkswap /swapfile #把刚才空间格式化成swap格式 su chmod 0600 /swapfile sudo swapon /swapfile #使用刚才创建的swap空间
sudo pip install Ninja --break-system-packages
sudo apt install cmakegit clone --depth 1 -b codon https://github.com/exaloop/llvm-project
cmake -S llvm-project/llvm -B llvm-project/build -G Ninja \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_INCLUDE_TESTS=OFF \
-DLLVM_ENABLE_RTTI=ON \
-DLLVM_ENABLE_ZLIB=OFF \
-DLLVM_ENABLE_TERMINFO=OFF \
-DLLVM_TARGETS_TO_BUILD=all
cmake --build llvm-project/build -j4
cmake --install llvm-project/build
sudo apt-get install clang
cd llvm-project
cd llvm
sudo sucmake -S . -B build -G Ninja \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_DIR=$(llvm-config --cmakedir) \
-DCMAKE_C_COMPILER=clang \
-DCMAKE_CXX_COMPILER=clang++
cmake --build build --config Release
cmake --install build --prefix=install
编译完成,释放临时增加的交换空间
swapoff -a