#-*- coding: utf-8 -*
import requests
from lxml import etree
#请求头和目标网址
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36'
}
##url = 'https://www.jianshu.com/u/472a595d244c'
url = 'http://www.mixdiy.com'
#第二种写法的 xpath
#获取所有 li标签
xpath_items = '//body[@class="home blog wp-custom-logo wp-embed-responsive"]/div'
#对每个 li标签再提取
xpath_link = './footer/div/a/@href'
xpath_title = './footer/div/a/text()'
##xpath_comment_num = './/div[@class="meta"]/a[2]/text()'
##xpath_heart_num = './/div[@class="meta"]/span/text()'
#获取和解析网页
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
dom = etree.HTML(r.text)
#获取所有的文章标签
items = dom.xpath(xpath_items)
#分别对每一个文章标签进行操作 将每篇文章的链接 标题 评论数 点赞数放到一个字典里
data = []
for article in items:
t = {}
t['link'] = article.xpath(xpath_link)[0]
t['title'] = article.xpath(xpath_title)[0]
#comment_num对应的标签里有两个文本标签 用 join方法将两个文本拼接起来
#strip()方法去除换行和空格
## t['comment_num'] = ''.join(article.xpath(xpath_comment_num)).strip()
## t['heart_num'] = article.xpath(xpath_heart_num)[0].strip()
data.append(t)
#打印结果
print(data[0]['link'])
if 'mixdiy.com' in data[0]['link']:
print('online')
else:
print('offline')
月度归档: 2022 年 6 月
python网络爬虫
https://www.jianshu.com/p/ff37a8524e72
一、前言
上一节我们讲了怎么批量下载壁纸,虽然爬虫的代码很简单,但是却有一个很重要的问题,那就是 xpath路径应该怎么写。
这个问题往往会被我们忽略,但 xpath路径的写法是很重要的。不同的 xpath路径写法会后续爬取代码会产生很大影响,而且不同的 xpath写法的稳定性也不同,能不能写出优雅稳定的代码就要看 xpath写得好不好了。
下面我们来讲讲为什么 xpath的写法这么重要
二、为什么 xpath写法很重要
我们拿几个例子来讲讲不同 xpath写法对代码的影响,以我的个人主页作为解析对象:
现在的需求是要爬取我个人主页里的文章列表,包括文章的链接、标题、访问量、评论数和点赞数量
个人主页
爬之前我们先分析一下
1、爬什么:文章链接文章的链接、标题、评论数和点赞数量
2、怎么爬:requests请求网页、xpath解析网页
接下来正式开始爬取:
第一步:分析网页,写出图片的 xpath路径
第二步:用 requests库获取网页
第三步:使用 lxml库解析网页
第四步:把爬取到的信息保存下来
我们一步一步来,首先分析网页,写出 xpath
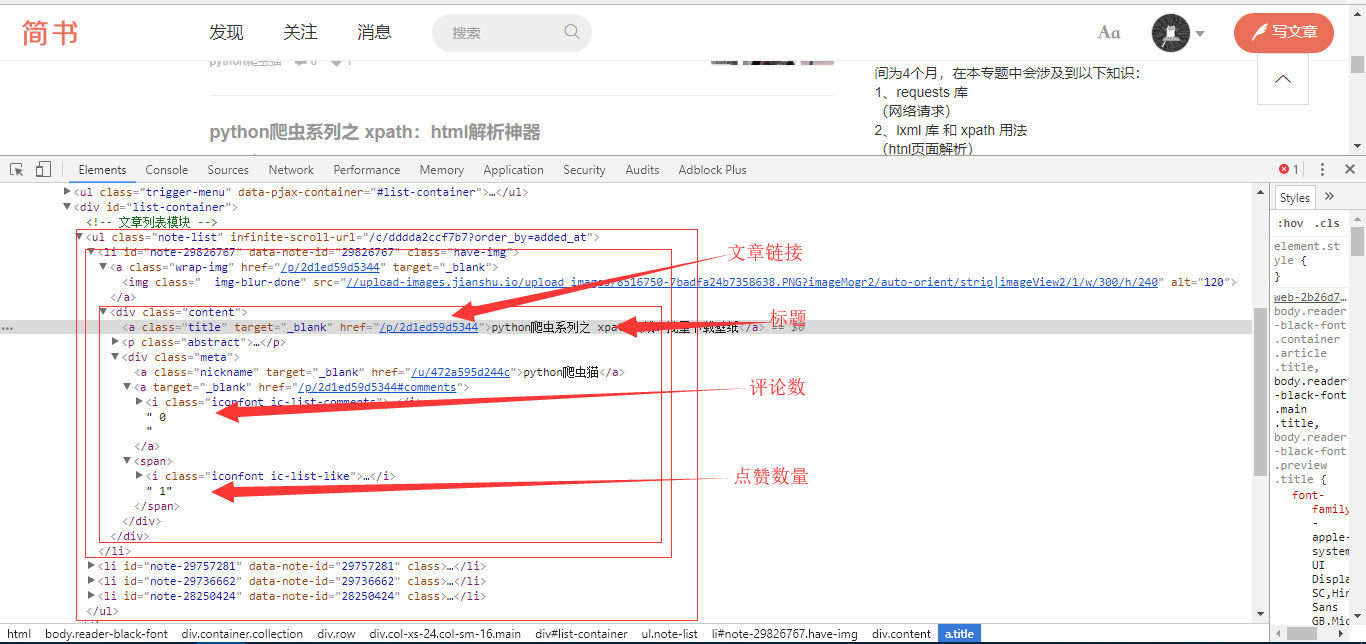
按 F12进入开发者模式,找到文章列表所在的标签
example-2.png
可以看到,文章列表是一个 ul标签,ul标签下的每一个 li标签分别代表一篇文章。
我们要爬的信息都在 class=”content”的 div标签下:
- 文章链接是第一个 a标签的 herf属性值
- 文章标题是第一个 a标签的文本属性的值
- 文章的评论数是 class=”meta”的 div标签下的第二个 a标签下的文本值
- 文章点赞数量是 class=”meta”的 div标签下的 span标签下的文本值
这时候 xpath有很多种写法,我写出其中的两种,一好一坏,大家可以试着判断一下哪个好哪个坏
第一种写法:
xpath_link = '//ul[@class="note-list"]/li/div/a/@href'
xpath_title = '//ul[@class="note-list"]/li/div/a/text()'
xpath_comment_num = '//ul[@class="note-list"]/li/div/div[@class="meta"]/a[2]/text()'
xpath_heart_num = '//ul[@class="note-list"]/li/div/div[@class="meta"]/span/text()'
第二种写法:
#获取所有 li标签
xpath_items = '//ul[@class="note-list"]/li'
#对每个 li标签再提取
xpath_link = './div/a/@href'
xpath_title = './div/a/text()'
xpath_comment_num = './/div[@class="meta"]/a[2]/text()'
xpath_heart_num = './/div[@class="meta"]/span/text()'
写好 xpath之后,我们开始第二步,获取网页
获取简书的网页如果我们还像之前那样直接请求的话,就会得到一个 403错误,这是因为没有设置请求头。
加上请求头就能解决了[]( ̄▽ ̄)*
第一种 xpath写法对应的代码:
#-*- coding: utf-8 -*
import requests
from lxml import etree
#请求头和目标网址
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36'
}
url = 'https://www.jianshu.com/u/472a595d244c'
#第一种写法的 xpath
xpath_link = '//ul[@class="note-list"]/li/div/a/@href'
xpath_title = '//ul[@class="note-list"]/li/div/a/text()'
xpath_comment_num = '//ul[@class="note-list"]/li/div/div[@class="meta"]/a[2]/text()'
xpath_heart_num = '//ul[@class="note-list"]/li/div/div[@class="meta"]/span/text()'
#获取和解析网页
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
dom = etree.HTML(r.text)
#所有的 链接 标题 评论数 点赞数
links = dom.xpath(xpath_link)
titles = dom.xpath(xpath_title)
comment_nums = dom.xpath(xpath_comment_num)
heart_nums = dom.xpath(xpath_heart_num)
#将每篇文章的链接 标题 评论数 点赞数放到一个字典里
data = []
for i in range(len(links)):
t = {}
t['link'] = links[i]
t['title'] = titles[i]
t['comment_num'] = comment_nums[i].strip()
t['heart_num'] = heart_nums[i].strip()
data.append(t)
#打印结果
for t in data:
print(t)
运行结果如下:
example-3
可以看到,第一篇和第三篇的 comment_num 没有获取到
第二种 xpath写法对应的代码:
#-*- coding: utf-8 -*
import requests
from lxml import etree
#请求头和目标网址
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36'
}
url = 'https://www.jianshu.com/u/472a595d244c'
#第二种写法的 xpath
#获取所有 li标签
xpath_items = '//ul[@class="note-list"]/li'
#对每个 li标签再提取
xpath_link = './div/a/@href'
xpath_title = './div/a/text()'
xpath_comment_num = './/div[@class="meta"]/a[2]/text()'
xpath_heart_num = './/div[@class="meta"]/span/text()'
#获取和解析网页
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
dom = etree.HTML(r.text)
#获取所有的文章标签
items = dom.xpath(xpath_items)
#分别对每一个文章标签进行操作 将每篇文章的链接 标题 评论数 点赞数放到一个字典里
data = []
for article in items:
t = {}
t['link'] = article.xpath(xpath_link)[0]
t['title'] = article.xpath(xpath_title)[0]
#comment_num对应的标签里有两个文本标签 用 join方法将两个文本拼接起来
#strip()方法去除换行和空格
t['comment_num'] = ''.join(article.xpath(xpath_comment_num)).strip()
t['heart_num'] = article.xpath(xpath_heart_num)[0].strip()
data.append(t)
#打印结果
for t in data:
print(t)
运行结果:
example-4
这里 comment_num成功获得了
仅仅从获取的结果来看,我们就可以判断第二种 xpath写法更好。
为什么第二种写法更好呢?
因为第二种方法把每一篇文章看作一个对象,这样后续的处理都是以对象为基本单位,对数据进行处理的时候过程更加清晰。
而第一种写法把链接、标题、评论数和点赞数量这四个分别用列表存储,这样虽然同样可以获得结果,但是再进行数据处理的时候就需要考虑怎么才能不破坏四个变量之间的一一对应关系。
用第二种方法就没有这个问题,因为在处理数据的时候它们都被看作同一个对象的组成部分,这本身就蕴含着蕴含着一种关系。
现在问题来了,平时我们在爬取数据的时候,怎么才能判断哪些数据是同一个对象呢?
这个其实很简单,在我们分析需求的时候就已经知道了,我们所需要数据的一个完整组合就是一个对象。
比如在本文的例子里,我们要爬取链接、标题、评论数和点赞数量,那么{链接,标题,评论数,点赞数量}就是一个对象。。
rc.local 使用python注意事项
在rc.local中使用python程序,一个注意事项是,加入在rc.local中如需sudo 运行python,则python的导入模块也需要用sudo install,否则会出现找不到模块的错误。
备份wordpress经验总结
wordpress网站备份总结
1、压缩/var/www/html目录
2、如果压缩文件很大则分割后再传输
3、在wordpress后台使用导出工具导出xml备份文件
4、将html目录压缩文件和导出的xml文件拷贝到新站
5、使用cat组合分割的压缩文件并解压到html目录下(解压前删除html下的所有文件)
6、创建wordpress数据库
7、访问站点并进入wordpress后台导入备份的xml文件
注:
前提条件是在新的系统上已经配置好环境(包括php、sql)
如何修复WordPress图片裁剪错误
我们现在知道错误的样子。让我们进一步了解如何修复图像裁剪错误。
作为故障排除的第一步,我们检查服务器的PHP版本以及GD库。如果缺少GD库,我们安装它。但是,GD安装步骤因服务器类型而异。
对于RedHat/CentOS主机,我们运行命令
yum install php-gd
或者,如果是Ubuntu服务器,GD安装使用
apt-get install php-gd
在这里,我们还要确保WordPress软件包的版本与主机的PHP版本相匹配。
最后,要制作新安装的GD库,需要重启web服务器。我们在服务器中通过
/etc/init.d/httpd restart
修复错误后,在“媒体库”中,用户可以选择图像并“插入文章”,完美解决问题。
密码保护:wordpressxml
树莓派清华源镜像
Raspbian 镜像使用帮助
使用说明
首先通过 uname -m 确定你使用的系统的架构。选择你的 Raspbian 对应的 Debian 版本: Debian 9 (stretch) Debian 10 (buster) Debian 11 (bullseye)
sudo nano /etc/apt/sources.list
# aarch64 用户,用以下内容取代:
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye main contrib non-free
# deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye main contrib non-free
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye-updates main contrib non-free
# deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye-updates main contrib non-free
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye-backports main contrib non-free
# deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye-backports main contrib non-free
deb https://mirrors.tuna.tsinghua.edu.cn/debian-security bullseye-security main contrib non-free
# deb-src https://mirrors.tuna.tsinghua.edu.cn/debian-security bullseye-security main contrib non-freesudo nano /etc/apt/sources.list.d/raspi.list
# 编辑 `/etc/apt/sources.list.d/raspi.list` 文件,删除原文件所有内容,用以下内容取代:
deb http://mirrors.tuna.tsinghua.edu.cn/raspberrypi/ bullseye main注意:网址末尾的raspbian重复两次是必须的。因为 Raspbian 的仓库中除了APT软件源还包含其他代码。APT软件源不在仓库的根目录,而在raspbian/子目录下。
编辑镜像站后,请使用sudo apt-get update命令,更新软件源列表,同时检查您的编辑是否正确。
相关链接
Raspbian 链接
- Raspbian 主页: https://www.raspbian.org
- 文档:https://www.raspbian.org/RaspbianDocumentation
- Bug 反馈:https://www.raspbian.org/RaspbianBugs
- 镜像列表: http://www.raspbian.org/RaspbianMirrors
树莓派链接
- 树莓派基金会主页: https://www.raspberrypi.org/
- 树莓派基金会论坛 Raspberry Pi OS 版块: https://raspberrypi.org/forums/viewforum.php?f=66
backup wordpress website
wordpress完整的数据备份
我们在使用wordpress进行建站的时候,当网站建立完成之后,我们需要将网站的数据进行备份,以防止当网站服务器数据丢失,或者其他情况导致的数据丢失。
因此网站数据备份是非常重要的,如果遇到这种情况,我们辛辛苦苦制作好并上传好资料的网站,如果没有备份,那么就永远丢失找不回来啦。
因此这里我们介绍如何完整的备份好你的数据。
一般来说wordpress网站的数据包括2个方面,这两个都需要单独备份。
一个是文件,也就是你上传安装的主题、插件以及文章中的图片和其他附件,这些我们在服务器或者虚拟主机上直接压缩下载备份即可。
另一个是数据库,数据库是你的网站所有的设置,包括你的文章设置、菜单、主题选项、管理员账号密码等等信息都是保存在数据库中的。
完整的将网站数据进行备份
1.网站文件的备份
首先,我们需要将我们网站上所有的文件进行备份,找到你的网站根目录,一般来说根目录的名称是www、htdocs、wwwroot、public_html等等,
如果你找不到哪一个是根目录,那么可以逐个打开目录,查看目录下是否有三个文件夹wp-content、wp-admin、wp-includes三个文件夹,那么就是wordpress的根目录了。
找到根目录之后,将整个目录文件夹压缩为zip压缩包格式,下载到本地的电脑上进行保存,这样我们的文件就全部保存好了。
2.网站数据库的备份
网站数据库的备份需要你进入你的数据库管理。一般找到服务器数据库管理可以找到,大部分的服务器是使用phpmyadmin进行管理的,这里我们也使用phpmyadmin为例子进行介绍。
首先进入phpmyadmin,找到你的数据库,如果你不知道你的网站是安装在哪一个数据库的 ,那么可以看看下面的图片,这样的数据库结构就是你的wordpress网站数据:

如上图所示,这就是你的wordpress网站数据,如果你安装了多了wordpress网站,有多个这样的数据库,不知道哪一个是想要备份的,那么在左侧上图找到wp-options,点击一下进入这个表
可以看到两个数据,一个是home,一个是siteurl,还有可以看到你的网站标题和副标题,这样就很容易找到了:

找到你想要的数据库之后,退出这个options表,进入整个表单的列表 ,如上图所示,可以点击一下红框中的链接进入:

然后点击导出按钮,进入导出界面后选择选择自定义:

在下面的兼容选择一下myslq323 兼容模式:

然后在最后点击导出即可得到备份的sql文件。
这里需要注意的是,因为mysql不同的版本导入的数据可能出现问题,因此最大兼容旧版本可以导出多个版本进行备份,
这是以防止你的数据要迁移到别的数据库进行导入时遇到的问题,如果你只是单纯的备份,那么这里可以不需要选择最大兼容。
这两个文件保存在自己的电脑上进行备份,这样我们的数据就完全的导入完成了,明天我们将出一篇教程,如何将我们的备份数据进行恢复,届时你可以点击下一篇文章进行阅读。
压缩目录
1、把/home目录下面的mydata目录压缩为mydata.zip
zip -r mydata.zip mydata #压缩mydata目录
2、把/home目录下面的mydata.zip解压到mydatabak目录里面
unzip mydata.zip -d mydatabak
3、把/home目录下面的abc文件夹和123.txt压缩成为abc123.zip
zip -r abc123.zip abc 123.txt
4、把/home目录下面的wwwroot.zip直接解压到/home目录里面
unzip wwwroot.zip
5、把/home目录下面的abc12.zip、abc23.zip、abc34.zip同时解压到/home目录里面
unzip abc*.zip
6、查看把/home目录下面的wwwroot.zip里面的内容
unzip -v wwwroot.zip
7、验证/home目录下面的wwwroot.zip是否完整
unzip -t wwwroot.zip
8、把/home目录下面wwwroot.zip里面的所有文件解压到第一级目录
unzip -j wwwroot.zip
主要参数
-c:将解压缩的结果
-l:显示压缩文件内所包含的文件
-p:与-c参数类似,会将解压缩的结果显示到屏幕上,但不会执行任何的转换
-t:检查压缩文件是否正确
-u:与-f参数类似,但是除了更新现有的文件外,也会将压缩文件中的其它文件解压缩到目录中
-v:执行是时显示详细的信息
-z:仅显示压缩文件的备注文字
-a:对文本文件进行必要的字符转换
-b:不要对文本文件进行字符转换
-C:压缩文件中的文件名称区分大小写
-j:不处理压缩文件中原有的目录路径
-L:将压缩文件中的全部文件名改为小写
-M:将输出结果送到more程序处理
-n:解压缩时不要覆盖原有的文件
-o:不必先询问用户,unzip执行后覆盖原有文件
-P:使用zip的密码选项
-q:执行时不显示任何信息
-s:将文件名中的空白字符转换为底线字符
-V:保留VMS的文件版本信息
-X:解压缩时同时回存文件原来的UID/GID
备份wordpress网站
wordpress完整的数据备份
我们在使用wordpress进行建站的时候,当网站建立完成之后,我们需要将网站的数据进行备份,以防止当网站服务器数据丢失,或者其他情况导致的数据丢失。
因此网站数据备份是非常重要的,如果遇到这种情况,我们辛辛苦苦制作好并上传好资料的网站,如果没有备份,那么就永远丢失找不回来啦。
因此这里我们介绍如何完整的备份好你的数据。
一般来说wordpress网站的数据包括2个方面,这两个都需要单独备份。
一个是文件,也就是你上传安装的主题、插件以及文章中的图片和其他附件,这些我们在服务器或者虚拟主机上直接压缩下载备份即可。
另一个是数据库,数据库是你的网站所有的设置,包括你的文章设置、菜单、主题选项、管理员账号密码等等信息都是保存在数据库中的。
完整的将网站数据进行备份
1.网站文件的备份
首先,我们需要将我们网站上所有的文件进行备份,找到你的网站根目录,一般来说根目录的名称是www、htdocs、wwwroot、public_html等等,
如果你找不到哪一个是根目录,那么可以逐个打开目录,查看目录下是否有三个文件夹wp-content、wp-admin、wp-includes三个文件夹,那么就是wordpress的根目录了。
找到根目录之后,将整个目录文件夹压缩为zip压缩包格式,下载到本地的电脑上进行保存,这样我们的文件就全部保存好了。
2.网站数据库的备份
网站数据库的备份需要你进入你的数据库管理。一般找到服务器数据库管理可以找到,大部分的服务器是使用phpmyadmin进行管理的,这里我们也使用phpmyadmin为例子进行介绍。
首先进入phpmyadmin,找到你的数据库,如果你不知道你的网站是安装在哪一个数据库的 ,那么可以看看下面的图片,这样的数据库结构就是你的wordpress网站数据:
如上图所示,这就是你的wordpress网站数据,如果你安装了多了wordpress网站,有多个这样的数据库,不知道哪一个是想要备份的,那么在左侧上图找到wp-options,点击一下进入这个表
可以看到两个数据,一个是home,一个是siteurl,还有可以看到你的网站标题和副标题,这样就很容易找到了:
找到你想要的数据库之后,退出这个options表,进入整个表单的列表 ,如上图所示,可以点击一下红框中的链接进入:
然后点击导出按钮,进入导出界面后选择选择自定义:
在下面的兼容选择一下myslq323 兼容模式:
然后在最后点击导出即可得到备份的sql文件。
这里需要注意的是,因为mysql不同的版本导入的数据可能出现问题,因此最大兼容旧版本可以导出多个版本进行备份,
这是以防止你的数据要迁移到别的数据库进行导入时遇到的问题,如果你只是单纯的备份,那么这里可以不需要选择最大兼容。
这两个文件保存在自己的电脑上进行备份,这样我们的数据就完全的导入完成了,明天我们将出一篇教程,如何将我们的备份数据进行恢复,届时你可以点击下一篇文章进行阅读。
压缩目录
1、把/home目录下面的mydata目录压缩为mydata.zip
zip -r mydata.zip mydata #压缩mydata目录
2、把/home目录下面的mydata.zip解压到mydatabak目录里面
unzip mydata.zip -d mydatabak
3、把/home目录下面的abc文件夹和123.txt压缩成为abc123.zip
zip -r abc123.zip abc 123.txt
4、把/home目录下面的wwwroot.zip直接解压到/home目录里面
unzip wwwroot.zip
5、把/home目录下面的abc12.zip、abc23.zip、abc34.zip同时解压到/home目录里面
unzip abc*.zip
6、查看把/home目录下面的wwwroot.zip里面的内容
unzip -v wwwroot.zip
7、验证/home目录下面的wwwroot.zip是否完整
unzip -t wwwroot.zip
8、把/home目录下面wwwroot.zip里面的所有文件解压到第一级目录
unzip -j wwwroot.zip
主要参数
-c:将解压缩的结果
-l:显示压缩文件内所包含的文件
-p:与-c参数类似,会将解压缩的结果显示到屏幕上,但不会执行任何的转换
-t:检查压缩文件是否正确
-u:与-f参数类似,但是除了更新现有的文件外,也会将压缩文件中的其它文件解压缩到目录中
-v:执行是时显示详细的信息
-z:仅显示压缩文件的备注文字
-a:对文本文件进行必要的字符转换
-b:不要对文本文件进行字符转换
-C:压缩文件中的文件名称区分大小写
-j:不处理压缩文件中原有的目录路径
-L:将压缩文件中的全部文件名改为小写
-M:将输出结果送到more程序处理
-n:解压缩时不要覆盖原有的文件
-o:不必先询问用户,unzip执行后覆盖原有文件
-P:使用zip的密码选项
-q:执行时不显示任何信息
-s:将文件名中的空白字符转换为底线字符
-V:保留VMS的文件版本信息
-X:解压缩时同时回存文件原来的UID/GID
设置树莓派开关机指示灯
https://blog.csdn.net/zhufu86/article/details/99704074
怎样在树莓派系统启动时,就改变某一个GPIO为上拉或者下拉,现在我就来举例说明。
我有一个树莓派2B,安装的Raspbian系统。
首先确保安装了wiringpi和device-tree-compiler。
pi@raspberrypi:~ $ sudo apt-get install wiringpi device-tree-compiler
Reading package lists… Done
Building dependency tree
Reading state information… Done
device-tree-compiler is already the newest version (1.4.7-3+rpt1).
wiringpi is already the newest version (2.50).
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
1
2
3
4
5
6
7
然后查看wringpi的版本,以及系统硬件的情况。
pi@raspberrypi:~ $ gpio -v
gpio version: 2.50
Copyright (c) 2012-2018 Gordon Henderson
This is free software with ABSOLUTELY NO WARRANTY.
For details type: gpio -warranty
Raspberry Pi Details:
Type: Pi 2, Revision: 01, Memory: 1024MB, Maker: Embest
- Device tree is enabled.
*–> Raspberry Pi 2 Model B Rev 1.1 - This Raspberry Pi supports user-level GPIO access.
1
2
3
4
5
6
7
8
9
10
11
使用gpio readall可以读出所有GPIO的状态。
pi@raspberrypi:~ $ gpio readall
+—–+—–+———+——+—+—Pi 2—+—+——+———+—–+—–+
| BCM | wPi | Name | Mode | V | Physical | V | Mode | Name | wPi | BCM |
+—–+—–+———+——+—+—-++—-+—+——+———+—–+—–+
| | | 3.3v | | | 1 || 2 | | | 5v | | |
| 2 | 8 | SDA.1 | IN | 1 | 3 || 4 | | | 5v | | |
| 3 | 9 | SCL.1 | IN | 1 | 5 || 6 | | | 0v | | |
| 4 | 7 | GPIO. 7 | IN | 1 | 7 || 8 | 1 | ALT0 | TxD | 15 | 14 |
| | | 0v | | | 9 || 10 | 1 | ALT0 | RxD | 16 | 15 |
| 17 | 0 | GPIO. 0 | IN | 0 | 11 || 12 | 0 | IN | GPIO. 1 | 1 | 18 |
| 27 | 2 | GPIO. 2 | IN | 0 | 13 || 14 | | | 0v | | |
| 22 | 3 | GPIO. 3 | IN | 0 | 15 || 16 | 0 | IN | GPIO. 4 | 4 | 23 |
| | | 3.3v | | | 17 || 18 | 0 | IN | GPIO. 5 | 5 | 24 |
| 10 | 12 | MOSI | IN | 0 | 19 || 20 | | | 0v | | |
| 9 | 13 | MISO | IN | 0 | 21 || 22 | 0 | IN | GPIO. 6 | 6 | 25 |
| 11 | 14 | SCLK | IN | 0 | 23 || 24 | 1 | IN | CE0 | 10 | 8 |
| | | 0v | | | 25 || 26 | 1 | IN | CE1 | 11 | 7 |
| 0 | 30 | SDA.0 | IN | 1 | 27 || 28 | 1 | IN | SCL.0 | 31 | 1 |
| 5 | 21 | GPIO.21 | IN | 1 | 29 || 30 | | | 0v | | |
| 6 | 22 | GPIO.22 | IN | 1 | 31 || 32 | 0 | IN | GPIO.26 | 26 | 12 |
| 13 | 23 | GPIO.23 | IN | 0 | 33 || 34 | | | 0v | | |
| 19 | 24 | GPIO.24 | IN | 0 | 35 || 36 | 0 | IN | GPIO.27 | 27 | 16 |
| 26 | 25 | GPIO.25 | IN | 0 | 37 || 38 | 0 | IN | GPIO.28 | 28 | 20 |
| | | 0v | | | 39 || 40 | 0 | IN | GPIO.29 | 29 | 21 |
+—–+—–+———+——+—+—-++—-+—+——+———+—–+—–+
| BCM | wPi | Name | Mode | V | Physical | V | Mode | Name | wPi | BCM |
+—–+—–+———+——+—+—Pi 2—+—+——+———+—–+—–+
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
可以看出,GPIO#6,13,19,26(BCM编号)的默认状态如下表:(GPIO的硬件接口全部悬空的情况下)
BCM GPIO # 硬件接口 # 输入输出 上下拉 值
6 31 输入 未知 1
13 33 输入 未知 0
19 35 输入 未知 0
26 37 输入 未知 0
4个GPIO都是默认输入口,值为1的可能是上拉,值为0的可能是下拉。(只是可能)
现在我要尝试把这4个GPIO的状态改变为下表所示:
BCM GPIO # 硬件接口 # 输入输出 上下拉 值
6 31 输入 下拉 0
13 33 输入 上拉 1
19 35 输出 n.a. X
26 37 输出 n.a. X
新建一个文件mygpio-overlay.dts并编辑为如下内容:
/dts-v1/;
/plugin/;
/ {
compatible = “brcm,bcm2708”;
fragment@0 {
target = <&gpio>;
__overlay__ {
pinctrl-names = "default";
pinctrl-0 = <&my_pins>;
my_pins: my_pins {
brcm,pins = <6 13 19 26>; /* gpio no. */
brcm,function = <0 0 1 1>; /* 0:in, 1:out */
brcm,pull = <1 2 1 2>; /* 2:up 1:down 0:none */
};
};
};};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
brcm,pins = <6 13 19 26>; /* gpio no. / 一行说明要修改那几个GPIO brcm,function = <0 0 1 1>; / 0:in, 1:out / 一行为要设定的输入输出状态,0输入,1输出 brcm,pull = <1 2 1 2>; / 2:up 1:down 0:none */
一行为要设定的上拉下拉状态,2上拉,1下拉,0为悬空
我把输出也设了上拉和下拉,测试看看是什么效果。
然后将mygpio-overlay.dts文件编译为mygpio-overlay.dtb,并拷贝到/boot/overlays/目录
pi@raspberrypi:~ $ dtc -@ -I dts -O dtb -o mygpio-overlay.dtb mygpio-overlay.dts
pi@raspberrypi:~ $ sudo cp mygpio-overlay.dtb /boot/overlays/
pi@raspberrypi:~ $ sudo vi /boot/config.txt
1
2
3
编辑/boot/config.txt文件,在[pi4]部分之前加入一行device_tree_overlay=overlays/mygpio-overlay.dtb
device_tree_overlay=overlays/mygpio-overlay.dtb
[pi4]
1
2
3
如果没有[pi4],就直接在文件末尾加入这一行好了。
重启后,运行gpio readall看看。
pi@raspberrypi:~ $ gpio readall
+—–+—–+———+——+—+—Pi 2—+—+——+———+—–+—–+
| BCM | wPi | Name | Mode | V | Physical | V | Mode | Name | wPi | BCM |
+—–+—–+———+——+—+—-++—-+—+——+———+—–+—–+
| | | 3.3v | | | 1 || 2 | | | 5v | | |
| 2 | 8 | SDA.1 | IN | 1 | 3 || 4 | | | 5v | | |
| 3 | 9 | SCL.1 | IN | 1 | 5 || 6 | | | 0v | | |
| 4 | 7 | GPIO. 7 | IN | 1 | 7 || 8 | 1 | ALT0 | TxD | 15 | 14 |
| | | 0v | | | 9 || 10 | 1 | ALT0 | RxD | 16 | 15 |
| 17 | 0 | GPIO. 0 | IN | 0 | 11 || 12 | 0 | IN | GPIO. 1 | 1 | 18 |
| 27 | 2 | GPIO. 2 | IN | 0 | 13 || 14 | | | 0v | | |
| 22 | 3 | GPIO. 3 | IN | 0 | 15 || 16 | 0 | IN | GPIO. 4 | 4 | 23 |
| | | 3.3v | | | 17 || 18 | 0 | IN | GPIO. 5 | 5 | 24 |
| 10 | 12 | MOSI | IN | 0 | 19 || 20 | | | 0v | | |
| 9 | 13 | MISO | IN | 0 | 21 || 22 | 0 | IN | GPIO. 6 | 6 | 25 |
| 11 | 14 | SCLK | IN | 0 | 23 || 24 | 1 | IN | CE0 | 10 | 8 |
| | | 0v | | | 25 || 26 | 1 | IN | CE1 | 11 | 7 |
| 0 | 30 | SDA.0 | IN | 1 | 27 || 28 | 1 | IN | SCL.0 | 31 | 1 |
| 5 | 21 | GPIO.21 | IN | 1 | 29 || 30 | | | 0v | | |
| 6 | 22 | GPIO.22 | IN | 0 | 31 || 32 | 0 | IN | GPIO.26 | 26 | 12 |
| 13 | 23 | GPIO.23 | IN | 1 | 33 || 34 | | | 0v | | |
| 19 | 24 | GPIO.24 | OUT | 0 | 35 || 36 | 0 | IN | GPIO.27 | 27 | 16 |
| 26 | 25 | GPIO.25 | OUT | 0 | 37 || 38 | 0 | IN | GPIO.28 | 28 | 20 |
| | | 0v | | | 39 || 40 | 0 | IN | GPIO.29 | 29 | 21 |
+—–+—–+———+——+—+—-++—-+—+——+———+—–+—–+
| BCM | wPi | Name | Mode | V | Physical | V | Mode | Name | wPi | BCM |
+—–+—–+———+——+—+—Pi 2—+—+——+———+—–+—–+
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
可以发现6,13,19,26四个GPIO的状态已经发生了变化,6的值变为0(应该是下拉了),13的值变为1(应该是上拉了)。另外可以看出,输出口指定上拉下拉是无效的,默认输出都是0。
举一反三,可以按照这个方法修改其他GPIO的状态。
【参考资料】
https://pinout.xyz
https://github.com/fivdi/onoff/wiki/Enabling-Pullup-and-Pulldown-Resistors-on-The-Raspberry-Pi
在config.txt里用gpio语法就可以给io配置的。
例如将GPIO18设为输出并置为低电平,写法如下:
gpio=18=op,dl
https://www.csdn.net/tags/OtDaAg2sMjIyMDQtYmxvZwO0O0OO0O0O.html
该指令允许在启动时将 GPIO 引脚设置为特定模式和值,这在以前需要自定义文件时是必需的。每行将相同的设置(或至少进行相同的更改)应用于一组引脚,可以是单个引脚 ()、引脚范围 (),也可以是逗号分隔的任意一个 ()。PIN 集后跟此列表中的一个或多个逗号分隔属性:gpiodt-blob.bin33-43-4,6,8=
ip- 输入
op- 输出
a0-a5- Alt0-Alt5
dh- 高电平驱动(用于输出)
dl- 低电平驱动(用于输出)
pu- 上拉
pd- 下拉
pn/np- 无拉
gpio设置按顺序应用,因此稍后出现的设置将覆盖较早出现的设置。